하둡,spark
MapReduce(맵리듀스) 프로그래밍
데이터왕
2024. 1. 17. 15:24
맵리듀스(MapReduce) 프로그래밍의 특징
- **불변성 데이터 셋:**
- 맵리듀스에서는 데이터 셋이 Key-Value 쌍의 집합으로 구성되며, 이 데이터 셋은 변경 불가능한(immutable) 특성을 가집니다. 즉, 한 번 생성된 데이터는 수정이 불가능하며 새로운 데이터를 생성해야 합니다. 이는 데이터 일관성을 유지하고 분산 처리를 간편하게 만듭니다. - **Map과 Reduce 오퍼레이션:**
- 데이터 조작은 맵(Map)과 리듀스(Reduce) 두 개의 기본 오퍼레이션으로 이루어집니다.
- **맵 오퍼레이션:** 입력 데이터의 각 요소에 대해 사용자가 정의한 함수(map 함수)를 적용하여 Key-Value 쌍을 생성합니다. 각 입력 데이터는 독립적으로 처리됩니다.
- **리듀스 오퍼레이션:** 맵 오퍼레이션의 결과로 생성된 Key-Value 쌍을 그룹화하고 사용자가 정의한 함수(reduce 함수)를 적용하여 최종 결과를 생성합니다. 리듀스 단계에서는 여러 맵 결과가 하나의 결과로 합쳐지는 과정이 발생합니다. - **연속적인 실행:**
- 맵리듀스에서는 맵과 리듀스 오퍼레이션이 항상 하나의 쌍으로 연속적으로 실행됩니다. 맵의 결과가 리듀스로 전달되어 처리되는 방식으로 동작합니다.
- 이러한 연속적인 실행은 데이터 처리 과정을 단순화하고, 병렬 처리를 쉽게 수행할 수 있도록 도와줍니다. - **맵 결과를 리듀스로 셔플링:**
- 맵리듀스 시스템은 맵 단계에서 생성된 결과를 리듀스로 셔플링(shuffling)합니다. 이 단계에서는 네트워크를 통해 데이터가 이동하게 되며, 각 리듀스 작업이 필요로 하는 맵의 출력을 수집하게 됩니다.
- 셔플링은 데이터를 그룹화하고 필요한 리듀스 작업에 전달하는 중요한 단계로, 전체 작업의 성능에 영향을 미침
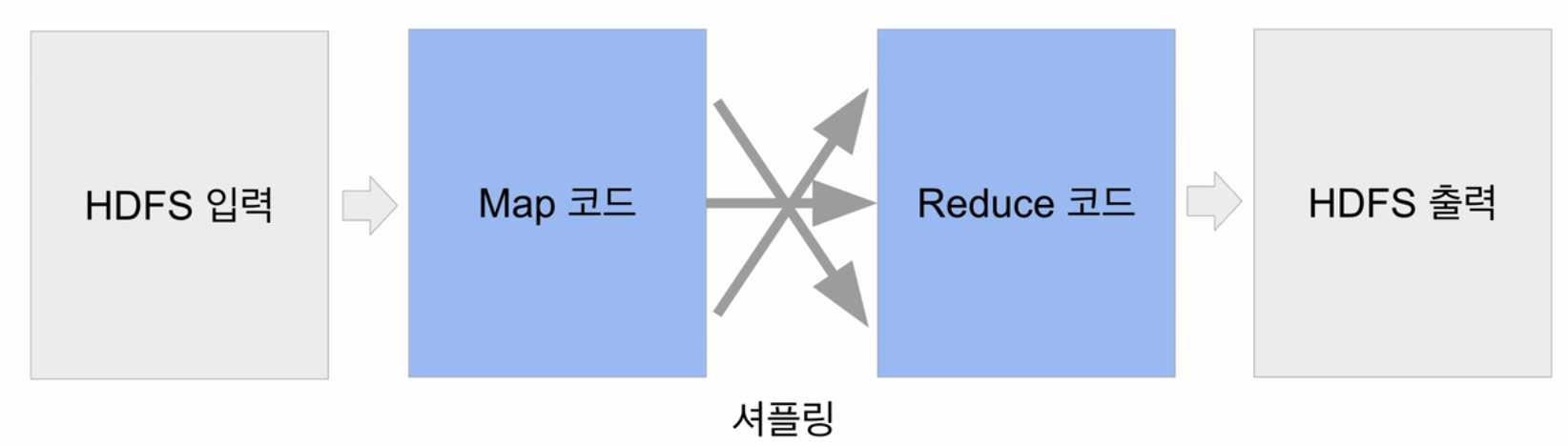
맵리듀스 방식의 코딩의 예
- 맵리듀스 프로그래밍은 대용량의 데이터에서 분산 병렬 처리를 효과적으로 수행하는 데에 활용됩니다. 여기에서는 대표적인 예제 중 하나인 로그 분석을 통한 사용자 행동 추적을 통해 맵리듀스가 어떻게 활용될 수 있는지를 설명하겠습니다.
| **목표:** - 대량의 로그 데이터에서 특정 이벤트의 발생 횟수를 계산하여 사용자 행동을 추적한다. **맵 단계 (Map Phase):** 1. **Input:** 대량의 로그 데이터 (로그당 한 줄씩) 2. **Map 함수:** 각 로그에서 특정 이벤트의 발생 여부를 체크하고, 발생했다면 해당 이벤트에 대한 Key-Value 쌍을 생성 (예: `(사용자ID, 1)`). 3. **Output:** 특정 이벤트가 발생한 로그들에 대한 Key-Value 쌍 ```python # 맵 함수 예제 (파이썬) def map_function(log_line): if '특정 이벤트 발생' in log_line: user_id = extract_user_id(log_line) return [(user_id, 1)] else: return [] ``` **셔플링 (Shuffling):** - Map 함수에서 생성된 (사용자ID, 1)의 쌍들이 리듀스 단계로 전달되기 위해 셔플링됨. **리듀스 단계 (Reduce Phase):** 1. **Input:** 셔플링된 (사용자ID, 1) 쌍들 2. **Reduce 함수:** 동일한 사용자ID를 가진 모든 쌍들의 값을 합산하여 해당 사용자의 특정 이벤트 발생 횟수를 계산. 3. **Output:** (사용자ID, 특정 이벤트 발생 횟수)의 쌍들. ```python # 리듀스 함수 예제 (파이썬) def reduce_function(user_id, counts): total_count = sum(counts) return (user_id, total_count) ``` 이렇게 맵리듀스를 사용하여 로그 데이터를 처리하면 대규모 데이터 세트에서도 효과적으로 특정 이벤트의 발생 횟수를 계산할 수 있습니다. 각각의 로그를 독립적으로 맵 함수에서 처리하고, 그 결과를 리듀스 함수에서 집계함으로써 분산 처리와 병렬 처리가 이루어집니다. 이를 통해 대규모 데이터에 대한 효율적인 분석 및 통계를 수행할 수 있습니다. |
맵리듀스 프로그래밍
- 이것은 맵리듀스 프로그래밍의 기본적인 동작을 나타내는 설명입니다. 여기에서는 Map 단계와 Reduce 단계에 대한 개념을 설명하겠습니다.
**Map 단계:**
- **입력:** Hadoop Distributed File System (HDFS)에 저장된 파일로부터 시스템에 의해 주어진다.
- **작업:** 각각의 (k, v) 쌍은 Map 함수에 의해 처리된다. Map 함수는 각 (k, v) 쌍을 새로운 키, 밸류 쌍의 리스트로 변환한다.
- **출력:** 변환된 리스트는 출력으로 사용되며, 각각의 새로운 (k', v') 쌍은 Hadoop 시스템에 의해 적절한 방식으로 처리된다.
**Reduce 단계:**
- **입력:** 맵 단계의 출력 중에서 동일한 키를 가진 키/밸류 페어들은 시스템에 의해 묶여 Reduce 함수에 전달된다.
- **작업:** Reduce 함수는 동일한 키를 가진 키/밸류 페어들의 밸류를 리스트로 받아들이고, 이를 새로운 키, 밸류 쌍으로 변환한다. 이 과정은 SQL에서의 GROUP BY와 유사하다.
- **출력:** 변환된 (k'', v'') 쌍은 HDFS에 저장되어 전체 작업의 최종 결과를 형성한다.
이렇게 MapReduce는 대용량 데이터를 분산하여 처리할 수 있는 프로그래밍 모델로, 각각의 맵과 리듀스 함수가 독립적으로 실행되어 데이터를 처리하고 집계합니다. 이를 통해 대규모 데이터셋에서 효과적인 분산 병렬 처리를 달성할 수 있습니다.
워드 카운트(MapReduce 프로그램 동작 예시)
| 맵리듀스 프로그래밍의 전형적인 예시 중 하나는 워드 카운트(Word Count)입니다. 이 예제에서는 대량의 텍스트 문서에서 각 단어의 출현 횟수를 계산하는 간단한 맵리듀스 작업을 수행합니다. 1. **맵 단계 (Map Phase):** - **Input:** 텍스트 문서들 - **Map 함수:** 각 문서에서 단어를 추출하고, 각 단어에 대해 1이라는 값을 부여한 Key-Value 쌍을 생성 - **Output:** (단어, 1)의 쌍들 ```python # 맵 함수 예제 (파이썬) def map_function(document): words = document.split() word_count_pairs = [(word, 1) for word in words] return word_count_pairs ``` 2. **셔플링 (Shuffling):** - 맵 함수에서 생성된 (단어, 1)의 쌍들이 리듀스 단계로 전달되기 위해 셔플링됩니다. 동일한 단어를 가진 쌍들이 같은 리듀스 작업으로 전송됩니다. 3. **리듀스 단계 (Reduce Phase):** - **Input:** 셔플링된 (단어, 1) 쌍들 - **Reduce 함수:** 동일한 단어를 가진 모든 쌍들의 값을 합산하여 해당 단어의 총 출현 횟수를 계산 - **Output:** (단어, 총 출현 횟수)의 쌍들 ```python # 리듀스 함수 예제 (파이썬) def reduce_function(word, counts): total_count = sum(counts) return (word, total_count) ``` 이 예제에서는 각 단어의 출현 횟수를 계산하기 위해 맵 함수에서 1이라는 값을 부여하고, 리듀스 함수에서 해당 단어의 총 출현 횟수를 합산합니다. 이러한 맵리듀스 프로그램을 실행하면 대량의 텍스트 문서에서 각 단어의 출현 횟수를 효과적으로 계산할 수 있습니다. 실제 맵리듀스 프로그래밍에서는 맵과 리듀스 함수를 작성하고, 맵리듀스 프레임워크 (예: Apache Hadoop)를 사용하여 클러스터에서 분산 처리를 수행합니다. |
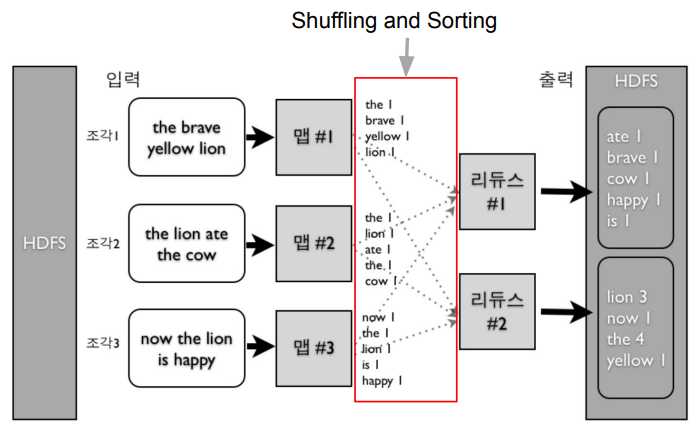
같은 키를 갖는 레코드들을 하나로 묶음
 |
 |
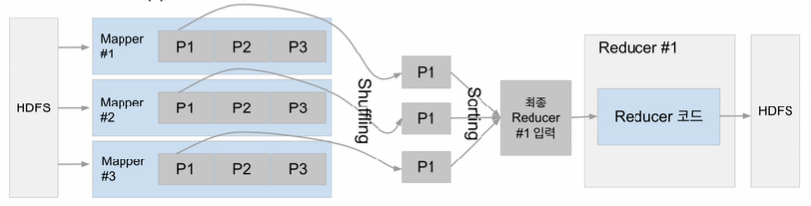
Shuffling (셔플링):
- **데이터 그룹화 (Data Grouping):** Mapper의 출력은 특정 키를 기준으로 여러 개의 그룹으로 나누어집니다. 이 과정에서 동일한 키를 가진 데이터가 같은 그룹에 속하게 됩니다.
- **파티셔닝 (Partitioning):** 그룹화된 데이터는 여러 파티션으로 나뉘어져 각각의 리듀스 태스크에 할당됩니다. 각 파티션은 리듀스 태스크로 전송될 것입니다.
- **정렬 (Sorting):** 파티션 내에서 키를 기반으로 정렬이 수행됩니다. 이로써 리듀스 태스크가 받는 입력 데이터가 키 순서대로 정렬되게 됩니다.
- **복사 (Copying):** 정렬된 데이터는 네트워크를 통해 복사되어 실제로 리듀스 노드로 이동합니다. 이 단계에서는 데이터의 크기와 네트워크 대역폭이 중요한 역할을 합니다. 크기가 크면 네트워크 병목현상을 초래한다.
Sorting (정렬):
- - **키를 기반으로 정렬:** Shuffling 중에는 주로 키를 기반으로 데이터가 정렬됩니다. 이로써 리듀스 태스크는 정렬된 순서대로 데이터를 처리할 수 있게 됩니다.
- - **입력 데이터 정렬:** 일반적으로 리듀스 태스크에 전달되는 입력 데이터는 키를 기준으로 정렬되어야 합니다. 이는 리듀스 함수가 효과적으로 동작하게 하기 위함입니다.
- Shuffling과 Sorting은 데이터 처리의 효율성과 성능에 큰 영향을 미치는 단계이며, 특히 대용량의 데이터를 처리할 때 이러한 단계를 최적화하는 것이 중요합니다.
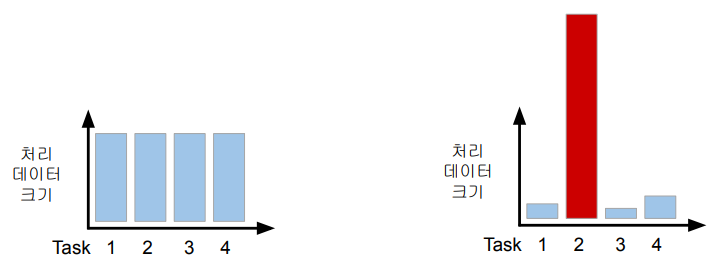
맵리듀스에서 생기는 data skew
- **데이터 크기 불균형의 문제:**
- MapReduce 작업에서 각각의 Map 또는 Reduce 태스크가 처리하는 데이터 크기에 불균형이 발생하는 경우가 있습니다.
- 특히, Reducer로 전송되는 데이터 크기에 큰 차이가 있을 수 있으며, 이는 Group By, Join 등의 작업에서 특히 두드러집니다. - **병렬 처리의 한계:**
- 불균형한 데이터 크기로 인해 각 태스크의 작업 속도가 차이가 나면, 병렬 처리의 이점을 충분히 활용하기 어려워집니다.
- 전체 작업의 속도는 가장 느린 태스크에 의해 결정되므로 일부 태스크가 과도한 데이터를 처리해야 할 경우 작업 전체가 느려집니다. - **Reducer로의 데이터 불균형:**
- Group By나 Join과 같은 작업에서는 일부 Reducer가 많은 양의 데이터를 처리하고 다른 Reducer는 적은 양의 데이터를 처리할 수 있습니다.
- 이는 전체 시스템의 성능에 영향을 미치며, 특히 Reducer의 수에 따라 메모리 에러 등의 문제가 발생할 수 있습니다. - **데이터 엔지니어링의 어려움:**
- 이러한 데이터 불균형은 빅데이터 시스템에서 흔한 문제로, 데이터 엔지니어는 이를 해결하기 위한 효과적인 전략을 필요로 합니다.
- 파티셔닝 전략, 리듀서 수 조절, 데이터 스케일링과 같은 기술적인 접근을 사용하여 데이터 불균형에 대응해야 합니다. - **시스템 성능 저하 가능성:**
- 데이터 불균형이 해결되지 않으면 전체 시스템의 성능이 저하될 수 있습니다.
- 따라서 데이터 엔지니어는 이러한 불균형을 모니터링하고 조정하여 전체 작업의 효율성을 유지해야 합니다.
MapReduce 프로그래밍의 문제점
- **낮은 생산성:**
- MapReduce는 특정한 프로그래밍 모델을 따르며, 이로 인해 프로그래머들이 가진 융통성이 부족합니다. Map과 Reduce 두 가지 오퍼레이션만을 제공하기 때문에 다양한 작업을 표현하기가 어려울 수 있습니다.
- 튜닝과 최적화도 쉽지 않은 편입니다. 특히, 데이터의 분포가 균등하지 않은 경우에는 성능 향상을 위한 조정이 어려울 수 있습니다. - **배치 작업 중심:**
- MapReduce는 기본적으로 대용량 데이터를 처리하는 데 중점을 두고 있어서 배치 작업에 적합합니다. 이는 대화형 또는 실시간 처리에는 적합하지 않은 특징입니다.
- Low Latency(낮은 응답 시간)보다는 Throughput(처리량)에 초점이 맞춰져 있어, 실시간 데이터 처리에는 적합하지 않을 수 있습니다. - **복잡한 프로그래밍 모델:**
- MapReduce 프로그래밍은 비교적 낮은 수준의 추상화를 제공하며, 개발자가 세부적인 작업을 직접 다루어야 합니다. 이로 인해 코드의 가독성이 떨어지고, 프로그램을 작성하는 데 높은 수준의 역량이 필요할 수 있습니다. - **데이터 이동 비용:**
- MapReduce는 중간 결과를 디스크에 저장하고, 이를 다시 읽어와서 다음 단계의 작업을 수행하는 방식으로 동작합니다. 이러한 디스크 I/O 작업은 데이터 이동 비용을 증가시키고, 성능을 저하시킬 수 있습니다.
이러한 문제점은 더 최신의 빅데이터 처리 프레임워크들이 나오게 된 동기 중 하나이며, Apache Spark, Apache Flink 등이 MapReduce의 한계를 극복하고자 나왔습니다. 이들 프레임워크들은 더 높은 수준의 추상화와 다양한 연산 지원으로 개발자의 생산성을 향상시키고, 실시간 처리와 반응성에 강점을 가지고 있습니다.
MapReduce 대안들의 등장
- 더 범용적인 대용량 데이터 처리 프레임웍들의 등장 ( YARN, Spark)
1. **YARN (Yet Another Resource Negotiator):**
- YARN은 Hadoop 2.x부터 도입된 클러스터 자원 관리 시스템으로, Hadoop 클러스터에서 여러 응용 프로그램을 실행하고 조율하는 역할을 합니다. YARN은 MapReduce 뿐만 아니라 다양한 응용프로그램들을 실행할 수 있게끔 범용적으로 설계되었습니다.
2. **Apache Spark:**
- Spark는 빅데이터 처리를 위한 오픈소스 클러스터 컴퓨팅 프레임워크로, RDD(Resilient Distributed Dataset)를 통한 데이터 처리를 지원합니다. MapReduce보다 빠른 속도와 다양한 연산 지원 등으로 인해 많은 관심을 받고 있습니다. - SQL의 컴백: Hive, Presto등이 등장
1. **Hive:**
- Hive는 데이터 웨어하우스 기능을 제공하는 데이터웨어하우스 기반의 데이터 처리 도구입니다. Hadoop 클러스터 위에서 동작하며, SQL과 유사한 HiveQL을 사용하여 데이터를 쿼리하고 처리합니다. Hive는 MapReduce를 기반으로 구현되어 있어서 대용량 ETL(Extract, Transform, Load) 작업에 적합합니다.
2. **Presto:**
- Presto는 Facebook에서 개발한 분산 SQL 쿼리 엔진으로, 대용량 데이터 처리에 특화되어 있습니다. Presto는 기존의 데이터 웨어하우스나 Hadoop과 연동하여 사용할 수 있으며, Adhoc 쿼리에 강점을 가지고 있습니다. 메모리를 주로 사용하여 빠른 쿼리 성능을 제공합니다.
3. **AWS Athena:**
- AWS Athena는 Presto 엔진을 기반으로 한 서버리스 쿼리 서비스로, S3에 저장된 데이터를 쿼리할 수 있습니다. 사용자는 쿼리당 비용을 지불하며, 특정한 클러스터를 관리하지 않아도 되므로 유연성이 높습니다.
이들 대안들은 각각의 특성에 따라 다양한 용도에 활용되고 있으며, MapReduce보다 더 높은 수준의 추상화, 빠른 처리 속도, SQL 기반의 쿼리 인터페이스 등을 제공하여 빅데이터 처리의 생산성과 성능을 향상시키고 있습니다.