데이터의 흐름
- (ETL) 데이터를 외부로부터 수집
Extract, Transform, Load - 데이터인프라(데이터레이크)에 저장
+ (ELT) 저장된 데이터로 더 활용하기 좋은 데이터로 가공 or 데이터 분석 - 수집할 데이터, 관리할 데이터가 많아지면, 이를 관리할 툴이 필요해짐(airflow)
+airflow 에서는 ETL을 DAG라고 부른다.

데이터레이크
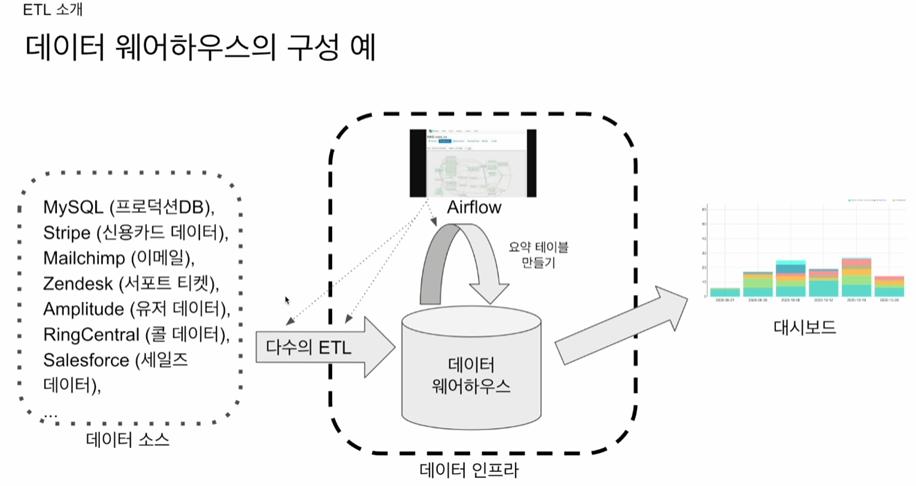
- 모든 데이터를 데이터웨어하우스에 다 저장할수 없다. 비용이 많이들기 때문.
- 핵심적인 데이터는 데이터 웨어하우스에 저장하고, 그외 것은 데이터레이크에 저장한다.
- 구조화+ 비구조화 데이터
- 보존 기한이 없는 모든 데이터를 원래 형태대로 보존. (S3 같은곳에 저장)
- 용량이 데이터웨어하우스보다 훨씬 크다.
- 외부 데이터를 데이터 레이크에 저장하고, spark등으로 데이터를 sql 기반으로 요약 재생산 후, 데이터 웨어하우스(redshift 등)에 저장
- 아래 그림에서 녹색 선들이 데이터 파이프라인이라 볼 수 있음

데이터 파이프라인
- 정의 : 데이터를 소스로부터 목적지로 복사하는 작업
+위 그림에서 녹색 선들이 데이터 파이프라인이라 볼 수 있음. - 작업 1 raw data etl jobs
1) 외부와 내부 데이터 소스에서 데이터를 읽음
2) 데이터 포맷 변환(크기가 커지면 spark 필요)
3) 데이터 웨어하우스 로드 - 작업2 summary/report jobs
1) 데이터웨어하우스 or 레이크 부터 데이터를 읽어 다시 데이터웨어하우스에 쓰는 ELT
2) raw data를 읽어서 리포트 형태나 요약 형태의 테이블을 다시 제작
3) ab 테스트 결과를 분석하는 파이프라인도 존재 - 작업3 production data jobs
1) 데이터웨어하우스로부터 데이터를 읽어 다른 저장소로 쓰는 ETL
+성능 이슈때문에 요약 정보가 프로덕션 환경에서 필요한경우
+머신러닝 모델에서 필요한 특성들을 미리 계산하는 경우
2) 이런경우 쓰이는 저장소 : NoSQL, 관계형데이터베이스(Mysql), 캐시(redis/memcache), 검색엔진(elasticsearch)
데이터 파이프라인을 만들때 고려할점
- 데이터가 작다면 가능하면 매번 테이블을 통체로 복사(full regresh)하는 방법을 쓸것
- 크기가 커지면 생긴 데이터를 그때그때 쌓는 방식(incremental update)도 가능하다.
- 데이터 업데이트 간격이 4시간인데 full regresh가 4시간 넘게 걸린다면 그경우도 incremental방식 필요
- incremental 방식에서 어려운점 : 특정 날짜의 업로드가 실패하는경우, 특정날짜부터 데이터의 포맷이 바뀌는경우
- incremental 방식이 가능하려면, api가 특정 날짜 기준 생성, 업데이트된 레코드를 따로 가져오는 기능이 있어야함
- 여러번 실행해도 버그(중복 등)없이 같은 결과를 보장하는 멱등성을 보장해야함
- 중요한 포인트는 transaction을 구현해야함
+ transaction예) 돈을 송금할때, 인출, 입금 두개 다 같이 이루어져야지 어느 하나만 실행되면 안됨 - 데이터 파이프라인의 원천부터 소비자까지의 전체적인 이력과 흐름을 추적 하고 문서화
예) 누가 데이터를 요청했는지, 보안데이터의 경우 누가 소비했는지도 중요. - 주기적으로 쓸모없는 데이터들을 삭제(리소스 관리)
+더이상 안쓰이는 데이터들도 많음 - 파이프라인 사고시 마다 리포트 쓰기. 사고 원인을 이해하고 재발 방지.(기술부채의 정도를 판단할수 있음)
+ 기술부채 : 기업이 기술적으로 해결해야 할 미해결 문제나 기술적인 결함이 쌓인정도 - 중요 데이터 파이프라인 입력, 출력을 테스트하는 테스트 코드를 작성.
입출력 레코드 수가 몇개인지(중복레코드체크), 요약 테이블을 만들고 pk(primary key) uniqueness가 보장되는지
+ pk :중복된 항목을 방지하며 효율적인 데이터 검색 및 무결성을 위한 고유 식별자
그럼에도 데이터 파이프라인을 만들때 어려운점
- 파이프라인이 늘어날수록 늘어나는 버그
- 파이프라인이 늘어날수록 유지보수 비용 급격히 증가
- 데이터 소스간의 연결이 많아지면(의존성이 증가하면), 한 곳의 문제가 전체적으로 어떤 영향을 미치는지
판단하는게 어려워짐(시각적 정리 필요)
결론 : 이들을 해결하는게 airflow
'airflow(에어플로우)' 카테고리의 다른 글
| airflow dag(task decorator 활용) 실습 3 (0) | 2024.01.02 |
|---|---|
| airflow dag(xcom 활용) 실습 2 (0) | 2024.01.02 |
| airflow dag(params 활용) 실습 1 (0) | 2024.01.02 |
| airflow dag(hello world) 실습 (0) | 2024.01.01 |
| airflow 기초 (0) | 2023.12.31 |