목표 : mysql 테이블 redshift로 복사하기
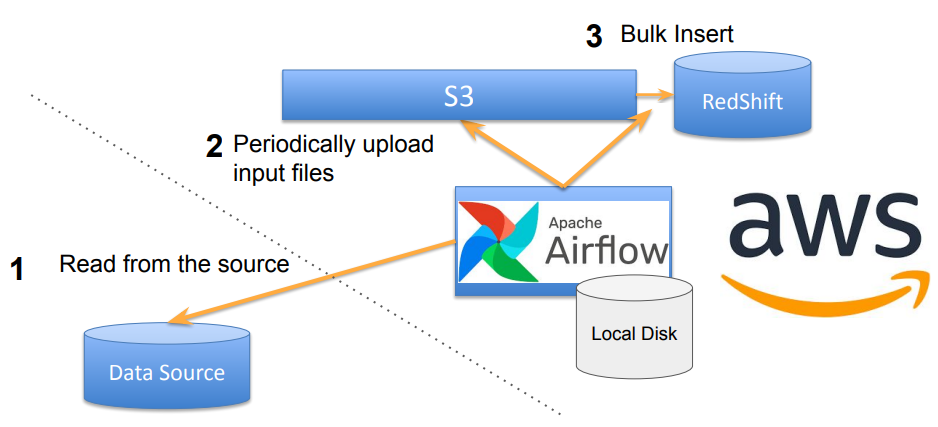
- 첫번째 방법(insert) : mysql -> airflow server(local)->redshift
+용량이 증가하면 insert commend가 오래걸림
+ 준비할것 : mysql->airflow 연결, airflow-> redshift 권한설정 - 두번째 방법(copy) : mysql -> airflow server(local)->amazon s3-> redshift
+준비할것 : mysql->airflow 연결 ,airflow->s3 권한설정 , s3 -> redshift 권한설정

s3 버킷,mysql 서버 구현은 따로 진행할것(중요정보라 밝히지 못함)
aws 권한설정
- airflow dag에서 s3 접근(쓰기권한)
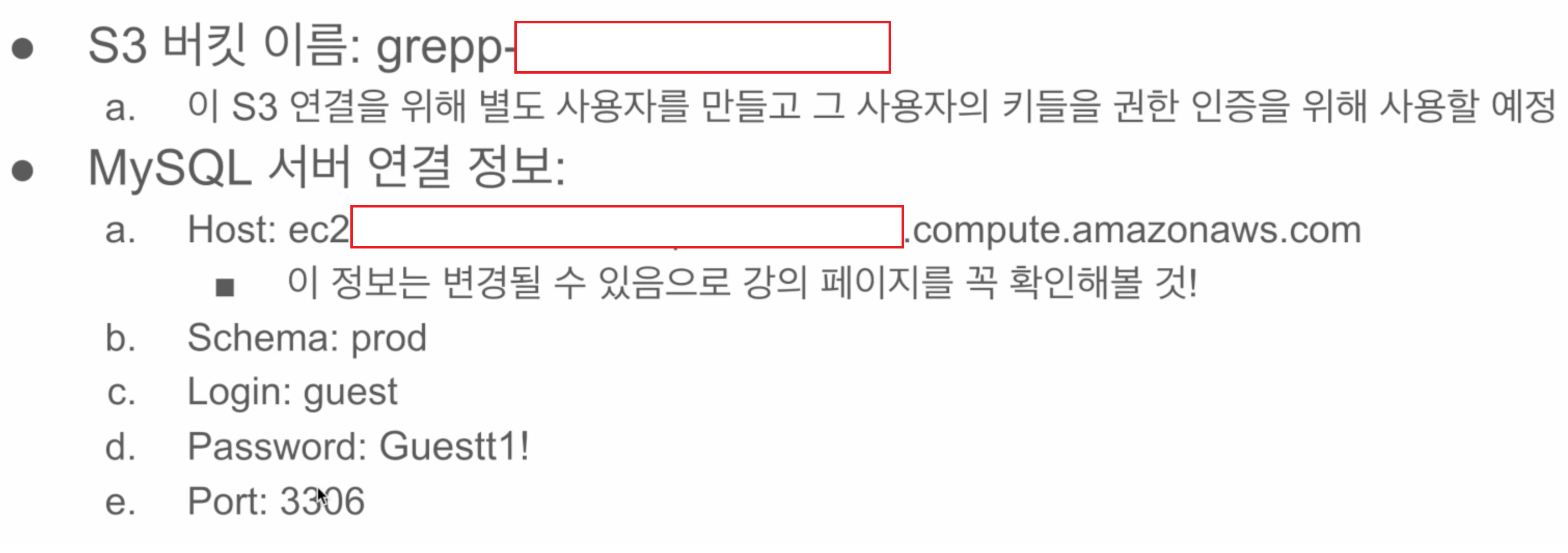
iam user를 만들고 s3 버킷에 대한 읽기/쓰기 권한 설정, access key와 secret key를 사용한다. - redshift가 s3 접근(읽기권한)
redshift에 s3를 접근할 수 있는 역할(role)을 만들고 이를 redshift에 지정
airflow에서 mysql 연결 설정

MySQLdb 에러발생시 https://allofdater.tistory.com/59 참조
aws s3 접근 방법 개요
- iam을 사용해 별도의 사용자를 만들고

- 그 사용자에게 해당 s3 bucket을 읽고 쓸 수 있는 권한을 제공(특정 s3의 권한만 주는게 좋음)

- custom policy 내용 아래로 수정

- 그 사용자의 access key id와 secret access key를 사용(두개 따로 잘 보관해놀것, 재발급X)

- airflow에서 s3 연결 설정
mysql (이미 제작된 실습) 테이블(oltp, production database)

redshift (oltp, data warehouse)에 해당 테이블생성

새롭게 사용할 operator
- SqlToS3Operator : MySQL SQL 결과 -> S3
(s3://grepp-data-engineering/{본인ID}-nps)
s3://s3_bucket/s3_key - S3ToRedshiftOperator : S3 -> Redshift 테이블
(s3://grepp-data-engineering/{본인ID}-nps) -> Redshift (본인스키마.nps)
COPY command is used
airflow를 활용한 전체 실습 과정
full refrash 버전 코드
| # 필요한 Airflow 모듈 및 클래스 가져오기 from airflow import DAG from airflow.operators.python import PythonOperator from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator from airflow.models import Variable # 필요한 Python 표준 라이브러리 가져오기 from datetime import datetime from datetime import timedelta # DAG 정의 dag = DAG( dag_id='MySQL_to_Redshift', # DAG의 고유 식별자 start_date=datetime(2022, 8, 24), # DAG 실행 시작일 schedule='0 9 * * *', # DAG의 스케줄 (UTC 기준, 매일 9시에 실행) max_active_runs=1, # 최대 동시 실행 횟수 catchup=False, # 과거 실행 여부 default_args={ 'retries': 1, # 작업 재시도 횟수 'retry_delay': timedelta(minutes=3), # 작업 재시도 간격 } ) # Redshift 테이블 및 S3 버킷 관련 설정 schema = "본인id" # Redshift 스키마 table = "nps" # Redshift 테이블명 s3_bucket = "grepp-data-engineering" # S3 버킷명 s3_key = schema + "-" + table # S3 키 (파일 경로) # MySQL 데이터를 S3로 이동하는 작업 정의 mysql_to_s3_nps = SqlToS3Operator( task_id='mysql_to_s3_nps', # 작업 고유 식별자 query="SELECT * FROM prod.nps", # MySQL에서 데이터를 가져오는 쿼리 s3_bucket=s3_bucket, # 이동할 S3 버킷 s3_key=s3_key, # 이동할 S3 키 (파일 경로) sql_conn_id="mysql_conn_id", # MySQL 연결에 사용될 연결 ID aws_conn_id="aws_conn_id", # AWS 연결에 사용될 연결 ID verify=False, # SSL 인증서의 검증을 시행할지 여부 replace=True, # S3에 저장된 파일이 이미 존재할 경우 해당 파일을 교체(replace)할지 여부 pd_kwargs={"index": False, "header": False}, # DataFrame을 CSV로 변환할 때 인덱스 및 헤더의 포함 여부 dag=dag # DAG 연결 ) # S3에서 Redshift로 데이터를 이동하는 작업 정의 s3_to_redshift_nps = S3ToRedshiftOperator( task_id='s3_to_redshift_nps', # 작업 고유 식별자 s3_bucket=s3_bucket, # 읽어올 S3 버킷 s3_key=s3_key, # 읽어올 S3 키 (파일 경로) schema=schema, # Redshift 테이블의 스키마 table=table, # Redshift 테이블명 copy_options=['csv'], # COPY 명령에 사용되는 옵션 method='REPLACE', # 데이터 이동 방법 (REPLACE: 기존 데이터 대체) redshift_conn_id="redshift_dev_db", # Redshift 연결에 사용될 연결 ID aws_conn_id="aws_conn_id", # AWS 연결에 사용될 연결 ID dag=dag # DAG 연결 ) # 작업 간의 의존성 정의 mysql_to_s3_nps >> s3_to_redshift_nps |
incremental update 방식
- 테이블이 다음을 만족해야함 : 만들거나 생성될때 time이 기록돼야함 ,
만들때 : created(timestamp) , modified(timestamp)
수정할때 : modified(timestamp)
삭제할때 : deleted(boolean) 가 true로 바뀌어야함, (deleted가 True면 동작)modified(timestamp) - row_number로 구현하는경우
예) daily update 이고, A인 table을 mysql에서 읽어올때, row_number로 구현
1) redshift의 A테이블의 내용을 temp_A로 복사
2) A테이블의 레코드 중 modified의 날짜가 지난일(execution_date)에 해당하는 모든 레코드를 temp_A로 복사
select * from A where date(modified) = date(execution_date)
3) temp_A의 레코드들을 primary key를 기준으로 파티션한 다음에 modified 값을 기준으로 desc 정렬해서, 일렬번호가 1인 것들만 다시 A로 복사 - S3ToRedshiftOperator로 구현하는 경우
1) SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
2) method 파라미터로 “UPSERT”를 지정
3) upsert_keys 파라미터로 Primary key를 지정(앞서 nps 테이블이라면 id필드를 사용)
incremental update 코드
| # 필요한 Airflow 모듈 및 클래스 가져오기 from airflow import DAG from airflow.operators.python import PythonOperator from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator from airflow.models import Variable # 필요한 Python 표준 라이브러리 가져오기 from datetime import datetime from datetime import timedelta # DAG 정의 dag = DAG( dag_id='MySQL_to_Redshift_v2', # DAG의 고유 식별자 start_date=datetime(2023, 1, 1), # DAG 실행 시작일 schedule='0 9 * * *', # DAG의 스케줄 (UTC 기준, 매일 9시에 실행) max_active_runs=1, # 최대 동시 실행 횟수 catchup=False, # 과거 실행 여부 default_args={ 'retries': 1, # 작업 재시도 횟수 'retry_delay': timedelta(minutes=3), # 작업 재시도 간격 } ) # Redshift 테이블, S3 버킷, S3 키 관련 설정 schema = "본인id" # Redshift 스키마 table = "nps" # Redshift 테이블명 s3_bucket = "grepp-data-engineering" # S3 버킷명 s3_key = schema + "-" + table # S3 키 (파일 경로) # s3_key = schema + "/" + table # S3 키 (다른 형식의 예시) # MySQL 쿼리 정의 sql = "SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution_date }}')" # MySQL 데이터를 S3로 이동하는 작업 정의 mysql_to_s3_nps = SqlToS3Operator( task_id='mysql_to_s3_nps', # 작업 고유 식별자 query=sql, # MySQL에서 데이터를 가져오는 쿼리 s3_bucket=s3_bucket, # 이동할 S3 버킷 s3_key=s3_key, # 이동할 S3 키 (파일 경로) sql_conn_id="mysql_conn_id", # MySQL 연결에 사용될 연결 ID aws_conn_id="aws_conn_id", # AWS 연결에 사용될 연결 ID verify=False, # SSL 검증 여부 replace=True, # S3 파일 교체 여부 pd_kwargs={"index": False, "header": False}, # pandas DataFrame 설정 dag=dag # DAG 연결 ) # S3에서 Redshift로 데이터를 이동하는 작업 정의 s3_to_redshift_nps = S3ToRedshiftOperator( task_id='s3_to_redshift_nps', # 작업 고유 식별자 s3_bucket=s3_bucket, # 읽어올 S3 버킷 s3_key=s3_key, # 읽어올 S3 키 (파일 경로) schema=schema, # Redshift 테이블의 스키마 table=table, # Redshift 테이블명 copy_options=['csv'], # COPY 명령에 사용되는 옵션 redshift_conn_id="redshift_dev_db", # Redshift 연결에 사용될 연결 ID aws_conn_id="aws_conn_id", # AWS 연결에 사용될 연결 ID method="UPSERT", # 데이터 이동 방법 (UPSERT: 삽입 또는 갱신) upsert_keys=["id"], # UPSERT 작업에 사용될 키 dag=dag # DAG 연결 ) # 작업 간의 의존성 정의 mysql_to_s3_nps >> s3_to_redshift_nps |
redshift에게 s3 버켓에 대한 액세스 권한 지정(링크 참조)
https://docs.google.com/document/d/1FArSdUmDWHM9zbgEWtmYSJnxPXDX-LB7HT33AYJlWIA/edit
Redshift cluster 설정
docs.google.com
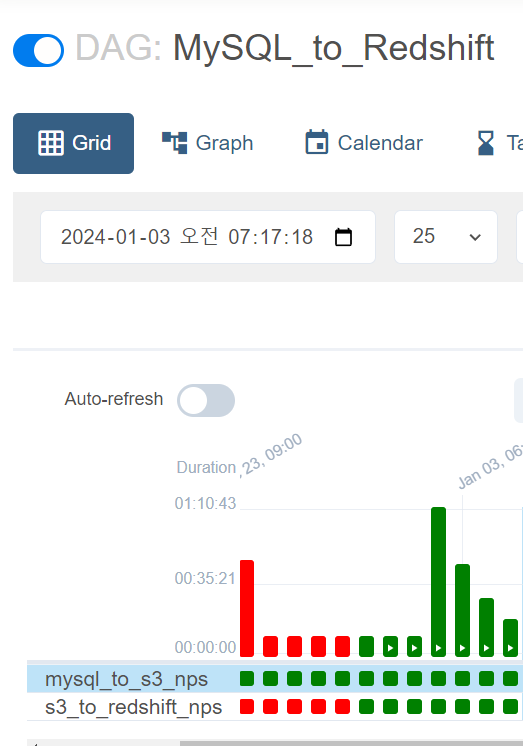
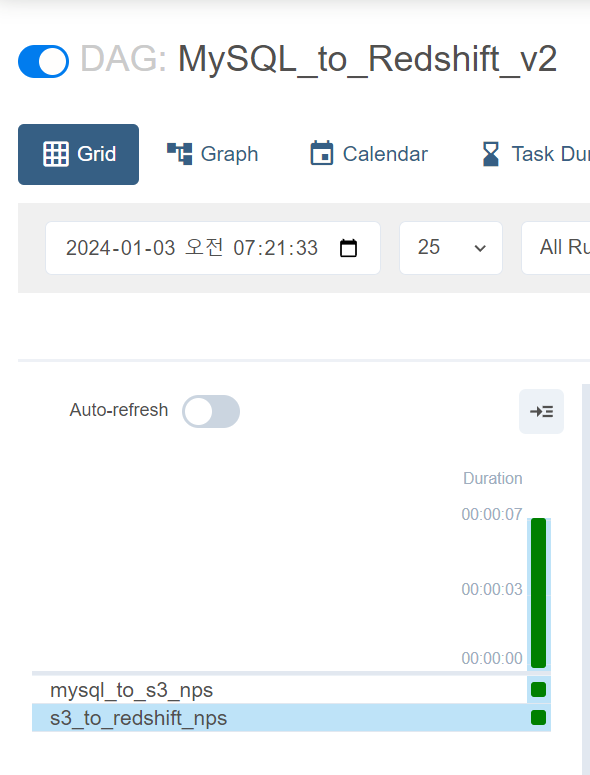
실습파일 본인 id로 수정(두개다 정상 실행완료)ㅇ
- weare@DESKTOP-BE1I4GE:~/airflow-setup/dags$ vim MySQL_to_Redshift_v2.py

'airflow(에어플로우)' 카테고리의 다른 글
| Airflow에서 _mysql is not defined 에러 (0) | 2024.01.03 |
|---|---|
| airflow에서 backfill 실행 (0) | 2024.01.03 |
| No module named MySQLdb 에러 (0) | 2024.01.03 |
| airflow에서 primary key 방법2 (0) | 2024.01.03 |
| backfill과 airflow (0) | 2024.01.02 |