하둡(Hadoop)은 대용량 데이터를 처리하기 위한 오픈 소스 분산 컴퓨팅 프레임워크입니다. 아래는 간단한 가이드라인을 제공하여 Ubuntu 리눅스 서버에 Hadoop 3.0을 의사분산 모드로 설치하는 방법입니다. 주어진 정보를 기반으로 설치를 진행해보세요.
(더 자세한건 : https://github.com/apache/hadoop)
**준비 사항:**
1) AWS 계정 및 EC2 인스턴스 (t2.medium) 보유.
2) Ubuntu 서버에 자바 8 설치.
1. 우분투 어카운트에 로그인( AWS 계정 및 EC2 인스턴스 계정)

2. Ubuntu 서버에 자바 8 설치:**
- ```bash
sudo apt update
sudo apt install openjdk-8-jdk-headless
#유저추가
sudo adduser hdoop
su - hdoopssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 생성된 공개 키를 authorized_keys 파일에 추가합니다.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# authorized_keys 파일에 대한 권한을 설정하여 소유자에게 읽기 및 쓰기 권한만 부여
chmod 0600 ~/.ssh/authorized_keys
```
# pw 없게 로그인 되게 설정
# RSA 알고리즘을 사용하여 SSH 키를 생성하고, -P 옵션을 이용하여 암호를 빈 문자열(암호없음)로 설정합니다.
3. Hadoop 다운로드 및 설치:**
- ```bash
# Hadoop 3.0 다운로드
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 압축 해제
tar xvf hadoop-3.3.4.tar.gz
# Hadoop 디렉토리로 이동
cd hadoop- 3.3.4
```
4. Hadoop 환경 설정:*
- # 로그인시마다 실행되는 파일 설정추가
vi .bashrc

- # 방금 설정한 설정 적용
source .bashrc - # 마스터 환경설정 파일 접속후 설정 변경
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh

- # 내임노드 관련 정보가 들어가는 파일, 수정
vi $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<!-- 임시 디렉터리 설정 -->
<property>
<!-- 하둡이 사용하는 임시 디렉터리의 이름을 지정합니다. -->
<name>hadoop.tmp.dir</name>
<!-- 임시 디렉터리의 경로를 지정합니다. -->
<value>/home/hdoop/tmpdata</value>
</property>
<!-- 하둡 분산 파일 시스템 (HDFS) 설정 -->
<property>
<!-- HDFS의 기본 이름을 지정합니다. -->
<name>fs.default.name</name>
<!-- 기본 HDFS 인스턴스의 주소 및 포트를 지정합니다. -->
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration> - # Hadoop의 추가적인 설정을 정의, replication 요소를 1로 추가, 설정추가
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<!-- Hadoop Configuration File -->
<configuration>
<!-- Hadoop NameNode 데이터 디렉터리 설정 -->
<property>
<!-- NameNode가 사용하는 데이터 디렉터리의 이름을 지정합니다. -->
<name>dfs.data.dir</name>
<!-- NameNode 데이터 디렉터리의 경로를 지정합니다. -->
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<!-- Hadoop DataNode 데이터 디렉터리 설정 -->
<property>
<!-- DataNode가 사용하는 데이터 디렉터리의 이름을 지정합니다. -->
<name>dfs.data.dir</name>
<!-- DataNode 데이터 디렉터리의 경로를 지정합니다. -->
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<!-- HDFS 복제 팩터(Replication Factor) 설정 -->
<property>
<!-- 파일의 복제본 수를 지정합니다. -->
<name>dfs.replication</name>
<!-- 파일의 단일 복제본을 사용하도록 설정합니다. -->
<value>1</value>
</property>
</configuration> - # Hadoop MapReduce 프레임워크에서 사용할 프레임워크의 yarn을 지정
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<!-- Hadoop Configuration File -->
<configuration>
<!-- MapReduce 프레임워크 설정 -->
<property>
<!-- 사용할 MapReduce 프레임워크의 이름을 지정합니다. -->
<name>mapreduce.framework.name</name>
<!-- YARN (Yet Another Resource Negotiator)을 사용하도록 설정합니다. -->
<value>yarn</value>
</property>
</configuration> - # YARN(Yet Another Resource Negotiator)의 여러 설정을 정의
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- YARN 노드 매니저의 보조 서비스 설정 -->
<property>
<!-- 노드 매니저가 사용할 보조 서비스의 이름을 지정합니다. -->
<name>yarn.nodemanager.aux-services</name>
<!-- 맵리듀스 셔플을 사용하도록 설정합니다. -->
<value>mapreduce_shuffle</value>
</property>
<!-- 맵리듀스 셔플 보조 서비스 클래스 설정 -->
<property>
<!-- 맵리듀스 셔플 보조 서비스의 클래스를 지정합니다. -->
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<!-- 맵리듀스 셔플 핸들러 클래스를 설정합니다. -->
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- YARN 리소스 매니저 호스트 설정 -->
<property>
<!-- YARN 리소스 매니저의 호스트 이름을 지정합니다. -->
<name>yarn.resourcemanager.hostname</name>
<!-- 로컬 호스트를 사용하도록 설정합니다. -->
<value>localhost</value>
</property>
<!-- YARN ACL 활성화 설정 -->
<property>
<!-- YARN ACL을 활성화 또는 비활성화합니다. -->
<name>yarn.acl.enable</name>
<!-- ACL을 비활성화하도록 설정합니다. -->
<value>0</value>
</property>
<!-- 노드 매니저 환경 변수 화이트리스트 설정 -->
<property>
<!-- 노드 매니저가 허용하는 환경 변수의 화이트리스트를 지정합니다. -->
<name>yarn.nodemanager.env-whitelist</name>
<!-- 허용된 환경 변수 목록을 지정합니다. -->
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
5. hdfs실행, yarn 실행
- # 초기화
hdfs namenode -format - # 디렉토리 이동
cd hadoop-3.3.4/sbin/ - #HDFS를 시작
./start-dfs.sh - #yarn을 시작
./start-yarn.sh - #exit 로 우분투로 나와서, Ubuntu 또는 Debian 기반 시스템에서 OpenJDK 8의 headless(그래픽 사용자 인터페이스 없음) 버전 설치, (GUI) 기능이 없는 환경에서 Java 애플리케이션을 실행하는 데 사용됨
exit
sudo apt install openjdk-8-jdk-headless - #하둡 계정으로 다시 접근
su - hdoop - #어떤 자바 프로그램이 돌고 있는지 봄
jps
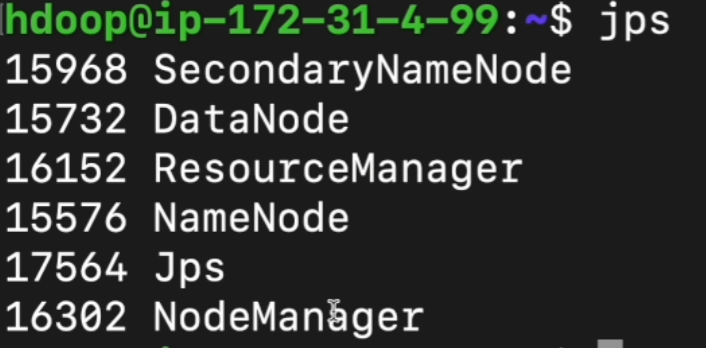
6. 하둡 실행
- ```bash
# Hadoop 포맷
bin/hdfs namenode -format
# Hadoop 시작
sbin/start-dfs.sh
```
웹 브라우저에서 `http://localhost:9870`으로 접속하여 Hadoop 관리자 페이지 확인.
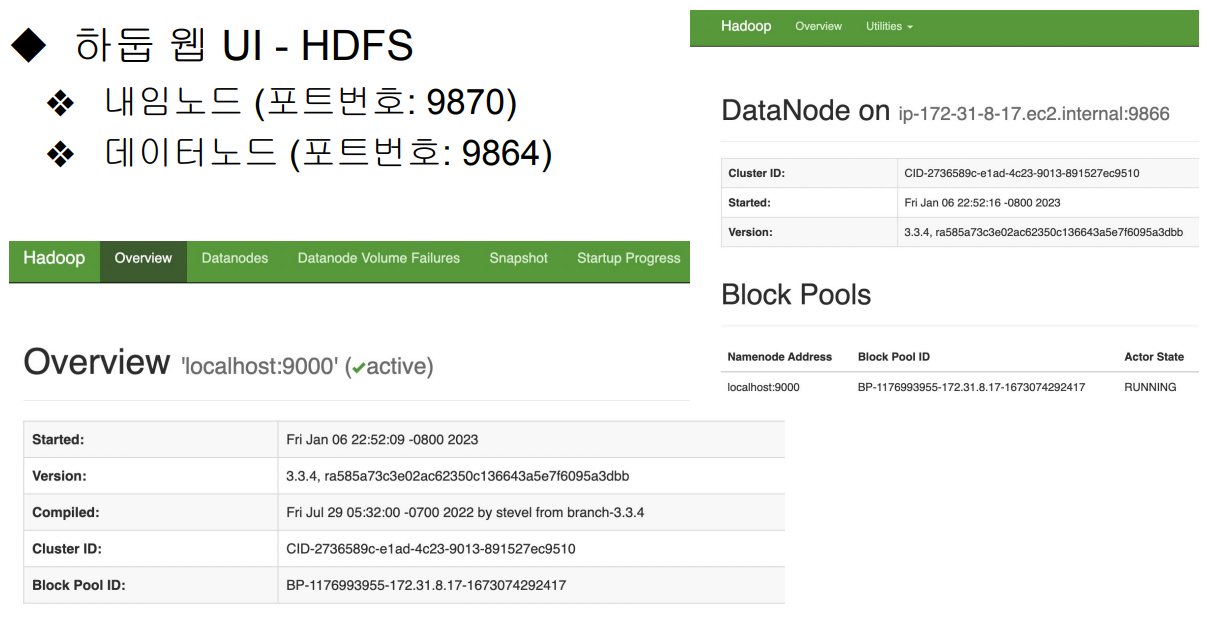
7. 맵리듀스 실행 실습
- #하둡 폴더로 이동
cd hadoop-3.3.4/
#유저 생성
bin/hdfs dfs dfs -mkdir /user
# /hdoop 폴더 제작
bin/hdfs dfs dfs -mkdir /user/hdoop
# input폴더 만듦
bin/hdfs dfs dfs -mkdir input
# words.txt 제작후 분석할 내용 입력
vi words.txt
the brave yellow lion the lion ate the cow now the lion is happy - 로컬 파일 시스템에 있는 words.txt 파일을 Hadoop 분산 파일 시스템 (HDFS)의 input 디렉토리로 복사
bin/hdfs dfs -put words.txt input - Hadoop 클러스터에서 WordCount 예제가 실행되어 입력 데이터에서 각 단어의 출현 빈도를 계산하고 output에 저장
bin/hadoop jar shqre/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount input output
+ bin/hadoop: Hadoop 명령어를 실행 / jar: JAR 파일을 실행 / 실행할 JAR 파일의 경로/ 실행할 Java 클래스인 wordcount / 입력 데이터가 위치한 HDFS의 경로/ 출력 결과를 저장할 HDFS의 경로 - bin/hdfs dfs -ls output
출력물 리스트 보기 - #출력물에서 하나 선택
bin/hdfs dfs -cat output/part-r-00000
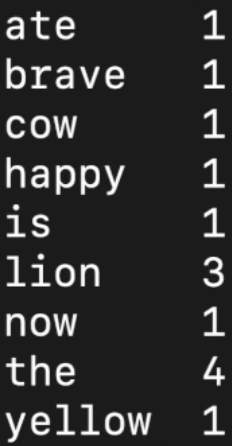
'하둡,spark' 카테고리의 다른 글
| spark 기초 (0) | 2024.01.18 |
|---|---|
| 맵리듀스(MapReduce) 문제점 (0) | 2024.01.18 |
| MapReduce(맵리듀스) 프로그래밍 (0) | 2024.01.17 |
| YARN (0) | 2024.01.16 |
| 하둡 기초 (0) | 2024.01.15 |