JOIN (조인) 개요:
- 정의:
- SQL 조인은 두 개 이상의 테이블을 공통 필드를 기반으로 결합하는 작업입니다.
- 이를 통해 서로 다른 테이블에 분산되어 있는 정보를 통합하고, 복잡한 쿼리를 수행할 수 있습니다. - 스타 스키마와의 관련:**
- 스타 스키마(Star Schema)는 데이터 웨어하우스에서 사용되는 스키마 중 하나로, 중앙의 대형 테이블(사실상 팩트 테이블)이 여러 작은 차원 테이블들과 조인하여 사용됩니다. - LEFT와 RIGHT 테이블:**
- 조인에서 왼쪽 테이블을 **LEFT**라고 하고, 오른쪽 테이블을 **RIGHT**라고 합니다. - 조인 결과:**
- JOIN의 결과는 양쪽의 필드를 모두 가진 새로운 테이블을 생성합니다.
- 조인의 방식에 따라 선택되는 레코드와 채워지는 필드가 달라집니다. - 조인 방식에 따른 차이:**
- **어떤 레코드들이 선택되는지?**
- INNER JOIN: 양쪽 테이블에서 매칭되는 레코드들만 선택됩니다.
- LEFT JOIN (또는 LEFT OUTER JOIN): 왼쪽 테이블의 모든 레코드가 선택되고, 오른쪽 테이블과 매칭되는 레코드가 있으면 함께 선택됩니다.
- RIGHT JOIN (또는 RIGHT OUTER JOIN): 오른쪽 테이블의 모든 레코드가 선택되고, 왼쪽 테이블과 매칭되는 레코드가 있으면 함께 선택됩니다.
- FULL JOIN (또는 FULL OUTER JOIN): 양쪽 테이블의 모든 레코드가 선택되며, 매칭되는 경우 함께 선택됩니다.
- **어떤 필드들이 채워지는지?**
- INNER JOIN: 매칭되는 필드만 선택됩니다.
- LEFT JOIN: 왼쪽 테이블의 필드는 항상 선택되고, 오른쪽 테이블과 매칭되는 경우 함께 선택됩니다.
- RIGHT JOIN: 오른쪽 테이블의 필드는 항상 선택되고, 왼쪽 테이블과 매칭되는 경우 함께 선택됩니다.
- FULL JOIN: 양쪽 테이블의 필드가 함께 선택되며, 매칭되는 경우 함께 선택됩니다.

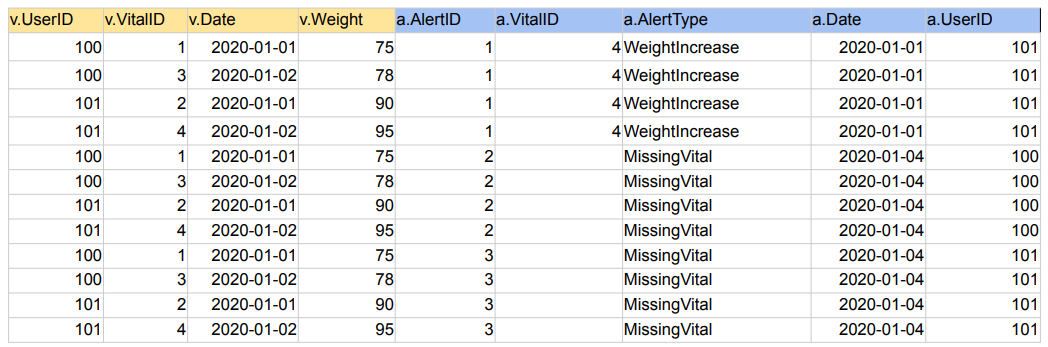
JOIN 실습 - 예제 데이터 준비
- 신체 데이터 이용 감시 시스템
- 경고(alert)조건 : 지병이2개이상, 5k이상 살이쪘을때, 2일이상 몸무게 재지 않았을때.

- INNER JOIN
1. 양쪽 테이블에서 매치가 되는 레코드들만 리턴함
2. 양쪽 테이블의 필드가 모두 채워진 상태로 리턴됨
SELECT *
FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;

- LEFT JOIN
1. 왼쪽 테이블(Base)의 모든 레코드들을 리턴함
2. 오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴됨
SELECT *
FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;

- FULL JOIN
1. 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴함
2. 매칭되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 리턴됨
SELECT *
FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;

- CROSS JOIN
1. 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴함
SELECT *
FROM raw_data.Vital v
CROSS JOIN raw_data.Alert a;
- SELF JOIN
1. 동일한 테이블을 alias를 달리해서 자기 자신과 조인함
SELECT *
FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID;

최적화 관점에서 본 조인의 종류들
- Shuffle JOIN:**
- **일반 조인 방식:**
- 특정 키를 기반으로 두 개 이상의 데이터셋을 결합하는 일반적인 조인 방식입니다.
- **Bucket JOIN:**
- 조인 키를 기반으로 조인을 수행하기 전에 두 데이터셋을 동일한 파티션으로 재분배하는 방식입니다.
- 조인 키를 사용하여 새로운 파티션을 생성하고, 각 파티션에 속한 데이터를 조인합니다.
- 이는 데이터를 효율적으로 분산하여 처리하기 위한 방법 중 하나입니다. - Broadcast JOIN:**
- **개요:**
- Broadcast JOIN은 큰 데이터셋과 작은 데이터셋 간의 조인을 최적화하는 방식입니다.
- 작은 데이터셋을 전체 클러스터에 복제(broadcasting)하여 특정 키를 기반으로 큰 데이터셋과 조인합니다.
- **적용 조건:**
- 데이터 프레임이 충분히 작은 경우에만 Broadcast JOIN을 사용하는 것이 효과적입니다.
- 충분히 작으면 작은 데이터 프레임을 다른 데이터 프레임이 있는 서버들로 뿌림
- `spark.sql.autoBroadcastJoinThreshold` 파라미터를 통해 어떤 크기 이하의 데이터프레임을 브로드캐스트할 것인지 결정할 수 있습니다. (exercutor에 지정된 메모리 값보다 작게)
- **장점:**
- 데이터를 모든 노드로 브로드캐스트하므로 특정 노드에서 조인을 수행할 수 있어 효율적입니다.
- 네트워크 비용이 감소하고 성능이 향상됩니다.
이러한 최적화 기법은 Spark에서 대용량 데이터셋을 다룰 때 성능을 향상시키기 위해 사용됩니다. 적절한 조인 전략을 선택하고 데이터셋을 파티셔닝하는 것은 Spark 작업의 성능과 확장성에 큰 영향을 미칩니다.
join 을 그림으로 이해
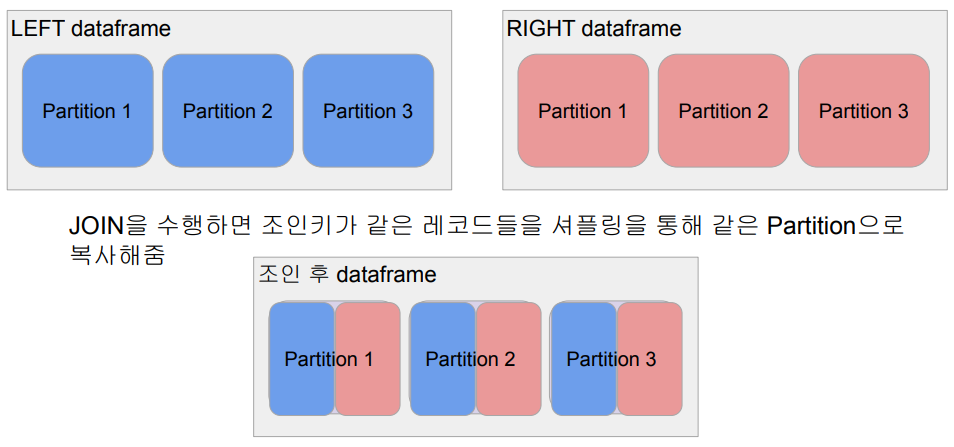
Broadcast JOIN을 그림으로 이해

'하둡,spark' 카테고리의 다른 글
| UDF 실습 (0) | 2024.01.28 |
|---|---|
| UDF(User Defined Function) 사용해보기. (1) | 2024.01.25 |
| spark SQL (1) | 2024.01.25 |
| spark 데이터프레임 실습5 (0) | 2024.01.24 |
| spark 데이터프레임 실습4 (0) | 2024.01.24 |