# PythonOperator는 그때 그때 선언해줘야한다 print_hello = PythonOperator( #task 이름 task_id = 'print_hello', #실행시키려는 함수이름 python_callable = print_hello, #이 Task가 속한 DAG를 지정 dag = dag)
# DAG 실행순서 할당 # 순서를 정하지 않으면 각각 독립적으로 동시에 실행됨 print_hello >> print_goodbye
2. Airflow Decorator 활용한 방법
Airflow Decorator :Airflow에서 사용되는 DAG를 정의하는 데코레이터(Decorator). 특정 기능이나 설정을 DAG 또는 DAG의 태스크에 적용하기 위한 방법으로 사용된다. Airflow Decorator는 자동으로 선언되기 때문에 PythonOperator에 비해 코드가 더 간단해진다.
실제 예 from airflow import DAG from airflow.decorators import task from datetime import datetime
with DAG( dag_id = 'HelloWorld_v2', start_date = datetime(2022,5,5), catchup=False, tags=['example'], schedule = '0 2 * * *' ) as dag:
# 함수이름이 기본으로 task id로 할당된다. print_hello() >> print_goodbye()
+ max_active_runs : 한번에 동시에 실행될수 있는 dag의 수. 일반적으로는 하나씩 해도 되지만, backfill을 할때는 여러개의 dag를 실행하며, 실행 시간을 줄일수 있다. max_active_tasks : 한번에 동시에 실행될수 있는 dag의 task 수. 리소스 사용을 조절하거나 부하를 관리하는 데 도움이됨 +airflow worker에 할당된 cpu의 총합= max_active의 한계
(핵심기능) backfill을 단순화 해줌 + backfill : 데이터 세트의 누락 또는 불완전한 데이터를 채우는 프로세스
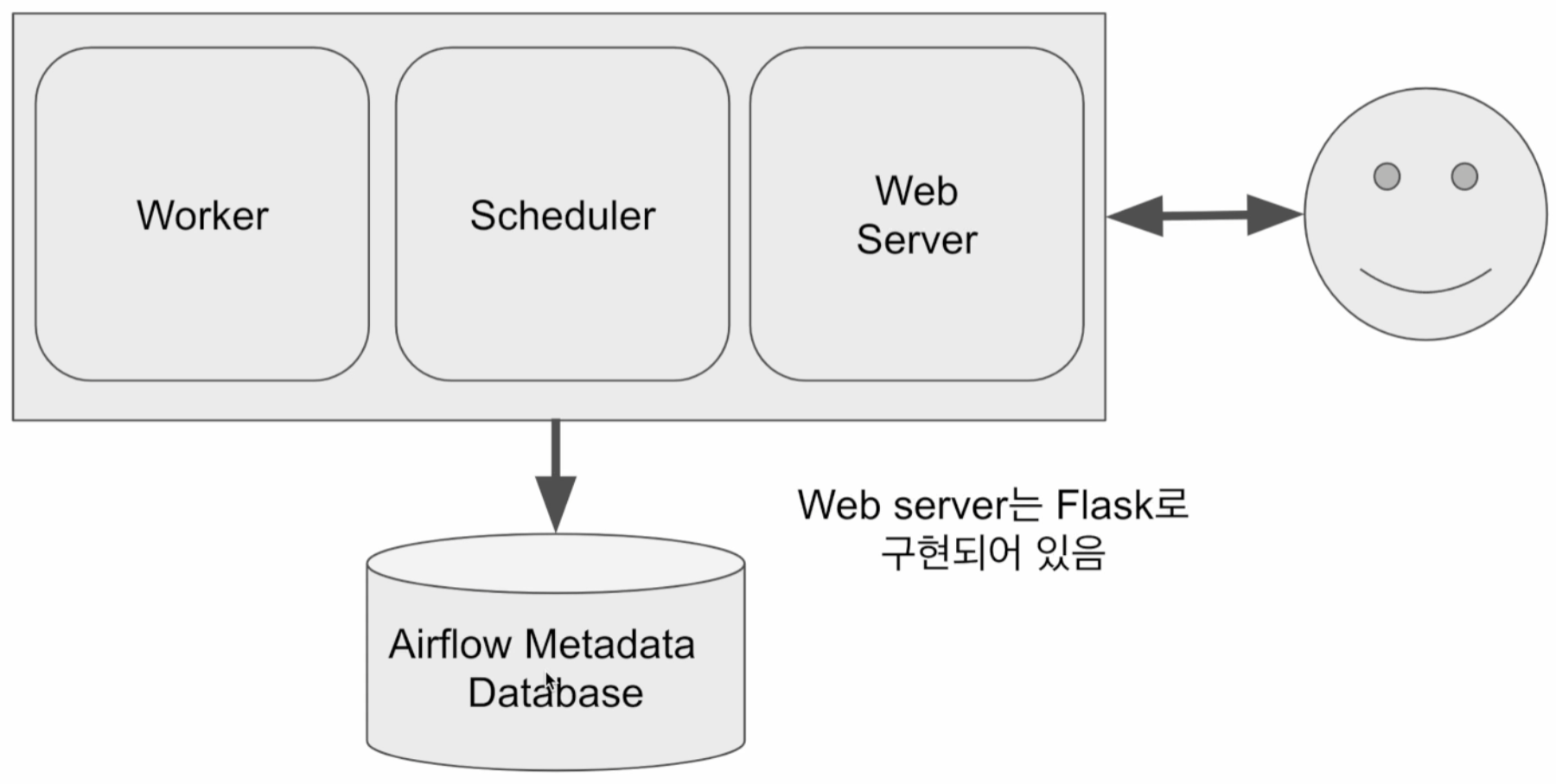
airflow 구조
웹서버 (Web Server): - Airflow 웹서버는 Airflow UI를 제공하며, DAGs(Directed Acyclic Graphs)를 시각적으로 관리하고 모니터링하는 데 사용됩니다. 웹 서버는 사용자 인터페이스를 통해 DAG 실행, 로그 확인, 스케줄러 상태 확인 등을 제공합니다.
스케줄러 (Scheduler): - Airflow 스케줄러는 정의된 DAG 실행 일정에 따라 작업을 예약하고 관리합니다. 주어진 DAG의 실행을 트리거하고 작업 간의 종속성을 관리하여 정의된 일정에 따라 작업을 실행합니다.
워커 (Worker): - Airflow 워커는 스케줄러에 의해 예약된 작업을 실행하는 역할을 합니다. 여러 워커가 병렬로 작업을 처리하여 시스템의 확장성을 지원합니다.
메타데이터 데이터베이스 (Metadata Database): - Airflow는 메타데이터 데이터베이스를 사용하여 실행된 DAG, 작업 실행 로그, 작업 상태 등의 메타데이터를 저장합니다. 이 메타데이터는 스케줄링, 모니터링 및 이력 추적을 위해 사용됩니다. 기본으로 sqlite가 설치된다. 그러나 실제로는 mysql,postgres를 설치해 사용한다.
큐 (Queue): - 다수서버 구성인 경우에만 사용된다. Airflow는 메시지 큐를 사용하여 작업 간의 메시지 전달을 처리합니다. 큐를 통해 스케줄러는 워커에 작업을 할당하고, 워커는 큐를 통해 스케줄러에 작업 완료 상태를 보고합니다.
실무에서 airflow 사용시 좋은 사양이 필요해진다면
서버 1개 사용시 : 서버의 사양을 높여나간다.
2개 이상 사용시 : 사양 증가의 한계치가 오면 서버를 늘린다. 이때 airflow 제공해주는 클라우드로 가는 것이 경제적 + 서버를 늘린다 : 보통 스케줄러 웹서버는 두고, worker용으로 서버를 늘린다.
airflow를 다수 서버로 구성할때
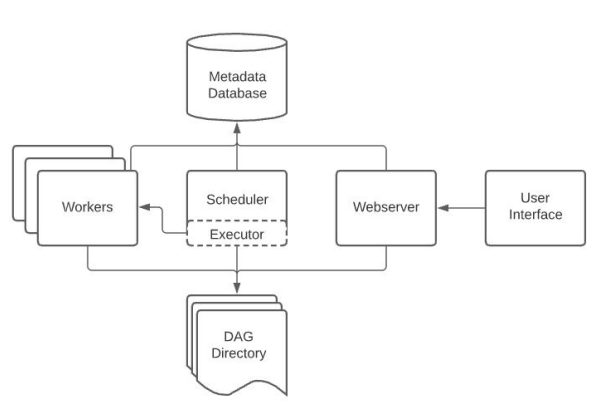
스케줄러 (Scheduler): - Airflow 스케줄러는 정의된 DAG(Directed Acyclic Graph)의 실행을 예약하고 관리하는 주체입니다. 스케줄러는 DAG 실행의 스케줄링과 종속성 그래프를 고려하여 작업을 실행합니다.
실행자 (Executor): - 실행자는 스케줄러에 의해 예약된 작업을 실행하는 역할을 합니다. Airflow에서는 여러 가지 종류의 실행자가 제공되며, 이들은 작업을 실행하는 방식에 대한 다른 전략을 제공합니다. 예를 들어, LocalExecutor는 단일 머신에서 작업을 실행하고, CeleryExecutor는 분산된 환경에서 작업을 실행합니다. +일부Executor의 경우 동작 특성에 따라 큐가 필요없이 단독으로 동작이 가능합니다.
큐 (Queue): - Airflow에서는 메시지 큐를 사용하여 작업 간의 통신을 조정합니다. 작업이 실행되기 전에 스케줄러는 해당 작업을 큐에 넣고, 실행자는 큐에서 작업을 가져와 실행합니다. 큐는 스케줄러와 실행자 간의 효율적인 통신을 도와줍니다.
스케줄러와 실행자 간의 관계: - 스케줄러는 DAG 실행을 예약하고 해당 작업을 큐에 추가합니다. - 실행자는 큐에서 작업을 가져와 실행합니다. 실행자는 실행 전에 작업을 먼저 클리어하고, 작업이 완료되면 그 결과를 다시 스케줄러에 보고합니다.
Executor의 종류
SequentialExecutor (큐가 필요없이 단독동작) - 특징: 작업을 순차적으로 실행하는 가장 간단한 실행자입니다. 한 번에 하나의 작업만 실행됩니다. - 사용 사례: 테스트 및 개발 환경에서 작은 규모의 작업을 처리하는 데 적합합니다. + 작업들을 순서대로 실행하므로 큐를 사용하지 않아도 됨
LocalExecutor (큐가 필요없이 단독동작) ) - 특징:동일한 머신에서 여러 작업을 병렬로 처리하는 실행자입니다. LocalExecutor는 멀티프로세스를 사용하여 작업을 실행합니다. - 사용 사례:작은 규모의 작업을 병렬로 처리하고자 할 때 사용됩니다. +작업들이 동일한 머신에서 실행되기 때문에 큐를 통한 통신 없이 바로 작업을 실행
CeleryExecutor: - 특징:Celery라는 분산 작업 큐를 사용하여 작업을 여러 워커에서 병렬로 실행하는 실행자입니다. - 사용 사례: 대규모의 분산 시스템에서 Airflow를 사용하고자 할 때 사용됩니다.
KubernetesExecutor: - 특징: Kubernetes 클러스터에서 각 작업을 컨테이너로 실행하는 실행자입니다. 각 작업은 별도의 파드로 실행 - 사용 사례:Kubernetes 환경에서 Airflow를 사용하고자 할 때 사용됩니다.
CeleryKubernetesExecutor: - 특징:Celery와 Kubernetes를 함께 사용하여 작업을 분산 환경에서 실행하는 실행자입니다. - 사용 사례:대규모의 분산 시스템에서 Airflow를 사용하고자 할 때, 특히 Celery와 Kubernetes를 함께 사용
DaskExecutor: - 특징:Dask를 사용하여 작업을 분산 처리하는 실행자입니다. Dask는 분산 컴퓨팅을 위한 라이브러리입니다. - 사용 사례: 대규모 작업을 분산 환경에서 효율적으로 처리하고자 할 때 사용됩니다.
airflow 개발의 장단점
장점 : 데이터 파이프라인을 세밀하게 제어, 다양한 데이터 소스와 데이터웨어하우스 지원, backfill이 쉬움
단점 : 배우기가 쉽지 않음, 개발환경 구성 어려움, 직접운영이 어렵고 서버가 늘어나면 클라우드 버전으로 전환 필요 +airflow 클라우드 버전 : GCP의 cloud composer , AWS의 managed workflows for apache airflow , AZURE의 data factory managed airflow
DAG란 무엇일까?
airflow에서 ETL를 부루는 명칭
DAG(Directed Acyclic Graph) : 작업(Task)의 흐름을 정의
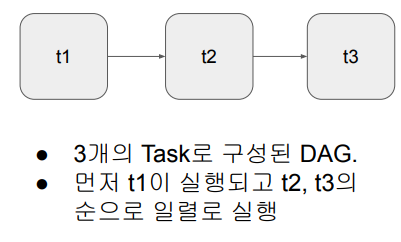
ETL dag는 3개의 task로 구성됨(extract, transform,load) +task : DAG 내에서 실제로 수행되어야 하는 작은 작업 단위. airflow의 오퍼레이터로 만들어지고, 오퍼레이터(클래스,함수)를 만들거나 직접 개발할 수 있다. 예) task1 = DummyOperator(task_id='task1', dag=dag) task2 = DummyOperator(task_id='task2', dag=dag) task1 >> task2
airflow 코드의 기본구조
DAG를 만듦 (이름, 실행주기, 실행날짜, 오너) 예) default_args = { 'owner': 'gwanghyeon', 'email': ['gwanghyeon @hotmail.com'], 'retries': 1, 'retry_delay': timedelta(minutes=3), } dag = DAG( "dag_v1", # DAG name start_date=datetime(2020,8,7,hour=0,minute=00), schedule="0 * * * *", tags=["example"], catchup=False, # common settings default_args=default_args )
+ schedule 실행 주기 설정방법
+ catchup : start_date를 과거로 설정했을때, 지난 기간동안 실행을 모두 따라잡을거면 True, 안할꺼면 False
DAG를 구성하는 task를 만듦(task 별로 적합한 오퍼레이터 선택)
예) 위 구조로 실행할때 코드 작성의 예
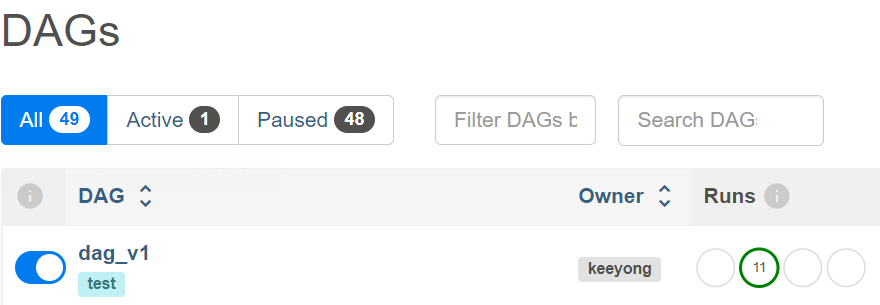
from airflow import DAG from airflow.operators.bash import BashOperator from datetime import datetime, timedelta default_args = { 'owner': 'gwanghyeon', 'start_date': datetime(2023, 5, 27, hour=0, minute=00), 'email': ['keeyonghan@hotmail.com'], # 재시도 횟수 'retries': 1, # 재시도 시간 간격 'retry_delay': timedelta(minutes=3), } test_dag = DAG( "dag_v1", # DAG name schedule="0 9 * * *", tags=['test'], catchUp=False, default_args=default_args )
task 제작(오퍼레이터 선택, 설정)과 순서 정의 # t1의 현재시간 출력 task t1 = BashOperator( task_id='print_date', bash_command='date', dag=test_dag)
# t2는 5초간 대기 후 종료 t2 = BashOperator( task_id='sleep', bash_command='sleep 5', dag=test_dag)
# t3는 서버의 /tmp 디렉토리의 내용 출력 t3 = BashOperator( task_id='ls', bash_command='ls /tmp', dag=test_dag)
# task 실행순서 지정 ( t1이 끝나고 t2와 t3를 병렬로 실행) t1 >> [ t2, t3 ]
웹 ui에서 dag 실행해보고 확인하기 1) http://localhost:8080/ 접속 2) id/pw 둘다 airflow로 초기설정 되어있음 3) 홈화면에서 해당 dag 찾아 접속해 해당 dag 확인, task 별 실행 상태(녹색네모) 클릭 후 log 확인 4) 코딩에서 구현했던 기능들이 구현됐는지 log에서 확인 t1의 현재시간 출력 task
t3는 서버의 /tmp 디렉토리의 내용 출력
커맨드 라인(우분투)에서 dag 실행해보고 확인하기 # 현재 스케줄러 컨테이너 id 확인 weare@DESKTOP-BE1I4GE:~/airflow-setup$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0b27bb5ccb0e apache/airflow:2.5.1 "/usr/bin/dumb-init …" 2 days ago Up 3 minutes (healthy) 8080/tcp airflow-setup_airflow-triggerer_1 0da253c77542 apache/airflow:2.5.1 "/usr/bin/dumb-init …" 2 days ago Up 3 minutes (healthy) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp airflow-setup_airflow-webserver_1 d306bc450764 apache/airflow:2.5.1 "/usr/bin/dumb-init …" 2 days ago Up 3 minutes (healthy) 8080/tcp airflow-setup_airflow-scheduler_1 c9cb62c2053a apache/airflow:2.5.1 "/usr/bin/dumb-init …" 2 days ago Up 3 minutes (healthy) 8080/tcp airflow-setup_airflow-worker_1 48ee152ae746 redis:latest "docker-entrypoint.s…" 2 days ago Up 3 minutes (healthy) 6379/tcp airflow-setup_redis_1 a5e756836619 postgres:13 "docker-entrypoint.s…" 2 days ago Up 3 minutes (healthy) 5432/tcp airflow-setup_postgres_1
# dag_v1의 task가 뭐있는지 확인(ls, print_date, sleep) (airflow)airflow tasks list dag_v1 /home/airflow/.local/lib/python3.7/site-packages/airflow/models/base.py:49 MovedIn20Warning: [31mDeprecated API features detected! These feature(s) are not compatible with SQLAlchemy 2.0. [32mTo prevent incompatible upgrades prior to updating applications, ensure requirements files are pinned to "sqlalchemy<2.0". [36mSet environment variable SQLALCHEMY_WARN_20=1 to show all deprecation warnings. Set environment variable SQLALCHEMY_SILENCE_UBER_WARNING=1 to silence this message.[0m (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9) ls print_date sleep
# dag_v1 DAG에서 print_date 태스크를 실행하고, 2023-05-23로 설정하여 해당 날짜에 대한 실행을 시뮬레이션해봄 (airflow)airflow tasks test dag_v1 print_date 2023-05-23
[2024-01-01 03:41:56,471] {subprocess.py:75} INFO - Running command: ['/bin/bash', '-c', 'date'] [2024-01-01 03:41:56,484] {subprocess.py:86} INFO - Output: [2024-01-01 03:41:56,489] {subprocess.py:93} INFO - Mon Jan 1 03:41:56 UTC 2024
-> print_date 결과가 2024년 1월 1일이 출력됐다. 그 이유는 catchUp=False 였기 때문에 중간의 실행은 생략되고, 현재 실행날짜 기준으로 출력됐다.
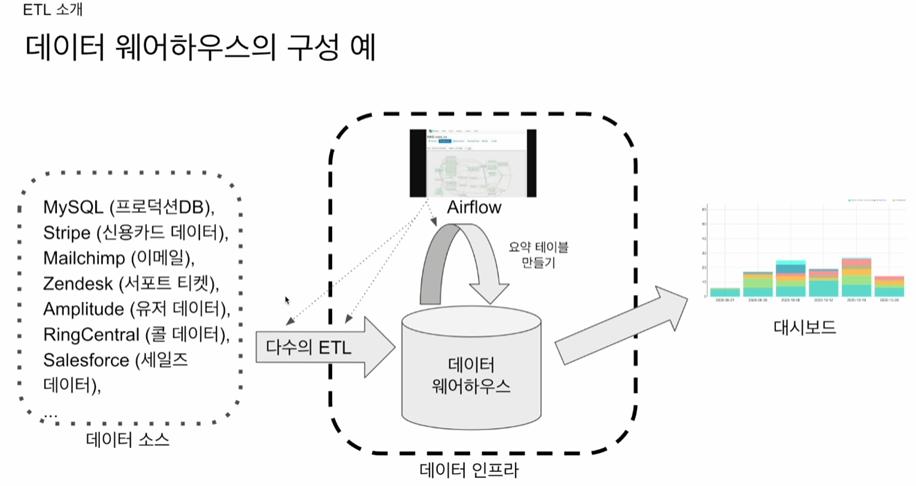
데이터인프라(데이터레이크)에 저장 + (ELT) 저장된 데이터로 더 활용하기 좋은 데이터로 가공 or 데이터 분석
수집할 데이터, 관리할 데이터가 많아지면, 이를 관리할 툴이 필요해짐(airflow) +airflow 에서는 ETL을 DAG라고 부른다.
데이터레이크
모든 데이터를 데이터웨어하우스에 다 저장할수 없다. 비용이 많이들기 때문.
핵심적인 데이터는 데이터 웨어하우스에 저장하고, 그외 것은 데이터레이크에 저장한다.
구조화+ 비구조화 데이터
보존 기한이 없는 모든 데이터를 원래 형태대로 보존. (S3 같은곳에 저장)
용량이 데이터웨어하우스보다 훨씬 크다.
외부 데이터를 데이터 레이크에 저장하고, spark등으로 데이터를 sql 기반으로 요약 재생산 후, 데이터 웨어하우스(redshift 등)에 저장
아래 그림에서 녹색 선들이 데이터 파이프라인이라 볼 수 있음
데이터 파이프라인
정의 : 데이터를 소스로부터 목적지로 복사하는 작업 +위 그림에서 녹색 선들이 데이터 파이프라인이라 볼 수 있음.
작업 1 raw data etl jobs 1) 외부와 내부 데이터 소스에서 데이터를 읽음 2) 데이터 포맷 변환(크기가 커지면 spark 필요) 3) 데이터 웨어하우스 로드
작업2 summary/report jobs 1) 데이터웨어하우스 or 레이크 부터 데이터를 읽어 다시 데이터웨어하우스에 쓰는 ELT 2) raw data를 읽어서 리포트 형태나 요약 형태의 테이블을 다시 제작 3) ab 테스트 결과를 분석하는 파이프라인도 존재
작업3 production data jobs 1) 데이터웨어하우스로부터 데이터를 읽어 다른 저장소로 쓰는 ETL +성능 이슈때문에 요약 정보가 프로덕션 환경에서 필요한경우 +머신러닝 모델에서 필요한 특성들을 미리 계산하는 경우 2) 이런경우 쓰이는 저장소 : NoSQL, 관계형데이터베이스(Mysql), 캐시(redis/memcache), 검색엔진(elasticsearch)
데이터 파이프라인을 만들때 고려할점
데이터가 작다면 가능하면 매번 테이블을 통체로 복사(full regresh)하는 방법을 쓸것
크기가 커지면 생긴 데이터를 그때그때 쌓는 방식(incremental update)도 가능하다.
데이터 업데이트 간격이 4시간인데 full regresh가 4시간 넘게 걸린다면 그경우도 incremental방식 필요
incremental 방식에서 어려운점 : 특정 날짜의 업로드가 실패하는경우, 특정날짜부터 데이터의 포맷이 바뀌는경우
incremental 방식이 가능하려면, api가 특정 날짜 기준 생성, 업데이트된 레코드를 따로 가져오는 기능이 있어야함
여러번 실행해도 버그(중복 등)없이 같은 결과를 보장하는 멱등성을 보장해야함
중요한 포인트는 transaction을 구현해야함 + transaction예) 돈을 송금할때, 인출, 입금 두개 다 같이 이루어져야지 어느 하나만 실행되면 안됨
데이터 파이프라인의 원천부터 소비자까지의 전체적인 이력과 흐름을 추적 하고 문서화 예) 누가 데이터를 요청했는지, 보안데이터의 경우 누가 소비했는지도 중요.
주기적으로 쓸모없는 데이터들을 삭제(리소스 관리) +더이상 안쓰이는 데이터들도 많음
파이프라인 사고시 마다 리포트 쓰기. 사고 원인을 이해하고 재발 방지.(기술부채의 정도를 판단할수 있음) + 기술부채 : 기업이 기술적으로 해결해야 할 미해결 문제나 기술적인 결함이 쌓인정도
중요 데이터 파이프라인 입력, 출력을 테스트하는 테스트 코드를 작성. 입출력 레코드 수가 몇개인지(중복레코드체크), 요약 테이블을 만들고 pk(primary key) uniqueness가 보장되는지 + pk :중복된 항목을 방지하며 효율적인 데이터 검색 및 무결성을 위한 고유 식별자
그럼에도 데이터 파이프라인을 만들때 어려운점
파이프라인이 늘어날수록 늘어나는 버그
파이프라인이 늘어날수록 유지보수 비용 급격히 증가
데이터 소스간의 연결이 많아지면(의존성이 증가하면), 한 곳의 문제가 전체적으로 어떤 영향을 미치는지 판단하는게 어려워짐(시각적 정리 필요)
해당 폴더로 이동 weare@DESKTOP-BE1I4GE:~$ cd airflow-setup
curl을 사용하여 URL에서 yaml 파일을 다운로드하고 -O 옵션을 사용하여 로컬에 파일을 저장 weare@DESKTOP-BE1I4GE:~/airflow-setup$ curl -LfO "https://airflow.apache.org/docs/apache-airflow/2.5.1/docker-compose.yaml" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 10493 100 10493 0 0 134k 0 --:--:-- --:--:-- --:--:-- 134k
yaml 파일에 정의된 도커 이미지를 다운로드. 로컬에 없는, postres, redis 등은 docker hub 에서 가져옴. weare@DESKTOP-BE1I4GE:~/airflow-setup$ docker-compose -f docker-compose.yaml pull WARNING: The AIRFLOW_UID variable is not set. Defaulting to a blank string. Pulling postgres ... done Pulling redis ... done Pulling airflow-init ... done Pulling airflow-triggerer ... done Pulling airflow-worker ... done Pulling airflow-scheduler ... done Pulling airflow-webserver ... done + postres, redis 는 외부에서 가져와서 airflow-가 앞에 붙지 않았다.
서버 실행 (에러발생) weare@DESKTOP-BE1I4GE:~/airflow-setup$ docker-compose -f docker-compose.yaml up WARNING: The AIRFLOW_UID variable is not set. Defaulting to a blank string. Creating airflow-setup_redis_1 ... done Creating airflow-setup_postgres_1 ... done Creating airflow-setup_airflow-init_1 ... done Creating airflow-setup_airflow-scheduler_1 ... done Creating airflow-setup_airflow-webserver_1 ... done Creating airflow-setup_airflow-triggerer_1 ... done Creating airflow-setup_airflow-worker_1 ... done Attaching to airflow-setup_redis_1, airflow-setup_postgres_1, airflow-setup_airflow-init_1, airflow-setup_airflow-scheduler_1, airflow-setup_airflow-webserver_1, airflow-setup_airflow-triggerer_1, airflow-setup_airflow-worker_1 airflow-init_1 | airflow-init_1 | WARNING!!!: AIRFLOW_UID not set! airflow-init_1 | If you are on Linux, you SHOULD follow the instructions below to set airflow-init_1 | AIRFLOW_UID environment variable, otherwise files will be owned by root. airflow-init_1 | For other operating systems you can get rid of the warning with manually created .env file:
AIRFLOW_UID not set! : AIRFLOW_UID가 설정되지 않았다는 내용, 필요한 폴더들을 만들고 환경변수가 저장될 위치가 필요하다.
에러 해결을 위해 airflow 운용에 필요한 폴더( dags , logs, plugins )들을 만들고 환경변수가 저장될 위치가 필요하다.
1) DAG 파일, 로그, 플러그인 등이 저장되는 경로를 설정 `mkdir -p ./dags ./logs ./plugins`: - `mkdir`: 디렉토리를 생성 - `-p`: 부모 디렉토리가 없으면 함께 생성합니다. - `./dags`: 현재 작업 디렉토리에 "dags"라는 디렉토리를 생성합니다. Airflow에서 DAG 파일을 저장하는 디렉토리 - `./logs`: 현재 작업 디렉토리에 "logs"라는 디렉토리를 생성합니다. Airflow 로그 파일이 저장되는 디렉토리입니다. - `./plugins`: 현재 작업 디렉토리에 "plugins"라는 디렉토리를 생성합니다. Airflow 플러그인이 위치하는 디렉토리
2) AIRFLOW_UID를 만들고 저장할 위치를 설정 `echo -e "AIRFLOW_UID=$(id -u)\nAIRFLOW_GID=0" > .env`: - `echo`: 화면에 텍스트를 출력하는 명령어입니다. - `-e`: 이 옵션은 이스케이프 시퀀스 (예: `\n` 등)를 해석하도록 합니다. - `"AIRFLOW_UID=$(id -u)\nAIRFLOW_GID=0"`: 환경 변수 파일인 `.env`에 저장할 내용으로, 현재 사용자의 UID(사용자 ID)를 `AIRFLOW_UID`로 설정하고, `AIRFLOW_GID`를 0으로 설정합니다. `id -u`는 현재 사용자의 UID를 가져오는 명령어입니다. - `> .env`: 앞서 설정한 내용을 현재 디렉토리에 `.env` 파일로 저장합니다.
위의 예시에서 `x-airflow-common` 속성은 `retries` 및 `retry_delay`와 같은 일반적으로 여러 곳에서 사용되는 설정을 담고 있습니다. 이렇게 하면 `tasks` 내의 각 태스크에서 이 속성을 참조하여 사용할 수 있습니다.
airflow에서 x-airflow-common 의 실제예
1) &airflow-common 아래 내용을 airflow-common으로 지정 2) _PIP_ADDITIONAM_REQUIREMENTS : 설치해야할 파이썬 모듈 이름들 지정 실행할때마다 모듈이 지워지는데 재설치할 수고가 적어짐, 모든 컨테이너에 모듈이 설치 돼서 모듈오류가 줄어듬 3) {AIRFLOW_PROJ_DIR:-.} : airflow yaml 파일이 있는 폴더의 이름
모듈 추가방식
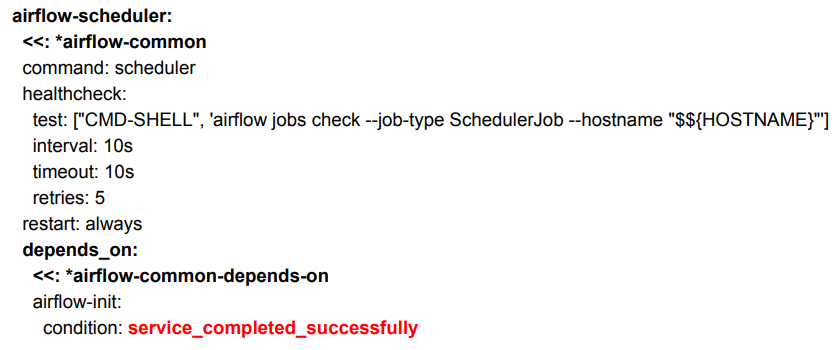
airflow-scheduler 서비스
1) <<: *airflow-common : 아까 &airflow-common 로 지정했던것 사용 2) airflow-init ~ : condition 충족하면 실행
dag 늘어날수록, 모듈들간의 호환성 출돌 이슈 + 수가 늘어날수록 해결하기가 불가능에 가까워짐
dag 늘어날수록 worker 부족 +싱글노드에서 멀티노드로 변화(서버증가)
바쁠때와 아닐때의 차이에 의해 서버낭비 발생 (내돈!!) +docker와 쿠버네티스가 도움이 될것임
위 문제들을 해결하는 방법
충돌이슈 : dag, task 코드를 docker image로 만들고 독립공간(docker 컨테이너) 을 만들어 실행 +개발환경과 프로덕션 환경을 동일하게 유지 가능
worker 부족 : 서버 사양 높이기(scale up),
서버분리후 증가(scale out)는 보통 aws 같은 클라우드 서비스,
쿠버네티스(k8s) 컨테이너 기술(필요할때 받아서 사용하고 반납) +전용 서버를 할당할 필요가 없음(배민라이더 인해 배달원 따로 고용 x)
서버낭비 : 쿠버네티스(k8s) 를 사용!
그래서 구체적으로 어떻게 해결하는데? (airflow에서 다음 방식으로 문제들을 해결하자)
airflow operator로 kubernetespod operator, dockeroperator 사용 KubernetesPodOperator : ubernetes 클러스터에서 실행되는 작업을 정의하는 데 사용,각 작업은 Kubernetes Pod 내에서 실행되며, 컨테이너 이미지, 리소스 할당 및 다른 Kubernetes 설정을 지정할 수 있다.
dockeroperator : 로컬 또는 원격 Docker 환경에서 실행되는 작업을 정의하는 데 사용, 각 작업은 Docker 컨테이너 내에서 실행되며, 사용할 이미지, 환경 변수 및 다른 Docker 설정을 지정할 수 있다
airflow executor(task들을 관리하고 실행)을 아래를 3개 사용 kubernetes Executor: Kubernetes의 강력한 컨테이너 오케스트레이션 기능을 활용하여 확장성이 뛰어나며 동적으로 자원을 할당
celerykubernetes E : Celery의 확장성과 Kubernetes의 컨테이너 관리 기능을 모두 활용
localKubernetes E :로컬 개발 머신에서 Kubernetes 클러스터를 모사하여 실행하는 에어플로우 실행자
+ 그외Executor 들 sequential executor :병렬 처리가 없어 단일 프로세스 내에서 작업이 실행, 성능이 낮지만, 테스트 및 디버깅 용이 localexecutor :로컬에서 병렬로 여러 작업을 실행하는 에어플로우 실행자 celery executor :Celery는 분산 작업 큐 시스템으로, 여러 워커에서 동시에 작업을 처리할 수 있도록 지원







 t3는 서버의 /tmp 디렉토리의 내용 출력
t3는 서버의 /tmp 디렉토리의 내용 출력