In [1]:
!pip install pyspark==3.3.1 py4j==0.10.9.5
Collecting pyspark==3.3.1
Downloading pyspark-3.3.1.tar.gz (281.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 281.4/281.4 MB 2.9 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting py4j==0.10.9.5
Downloading py4j-0.10.9.5-py2.py3-none-any.whl (199 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 199.7/199.7 kB 15.6 MB/s eta 0:00:00
Building wheels for collected packages: pyspark
Building wheel for pyspark (setup.py) ... done
Created wheel for pyspark: filename=pyspark-3.3.1-py2.py3-none-any.whl size=281845494 sha256=29e5202bc43907a8c41b7ffbdfc5a5bf38051efdf687cf46c521d0f4651d78ab
Stored in directory: /root/.cache/pip/wheels/0f/f0/3d/517368b8ce80486e84f89f214e0a022554e4ee64969f46279b
Successfully built pyspark
Installing collected packages: py4j, pyspark
Attempting uninstall: py4j
Found existing installation: py4j 0.10.9.7
Uninstalling py4j-0.10.9.7:
Successfully uninstalled py4j-0.10.9.7
Successfully installed py4j-0.10.9.5 pyspark-3.3.1
Spark Session: 생성
In [2]:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark UDF") \
.getOrCreate()
Dataframe/SQL에 UDF 사용해보기 #1
In [3]:
columns = ["Seqno","Name"]
data = [("1", "john jones"),
("2", "tracey smith"),
("3", "amy sanders")]
df = spark.createDataFrame(data=data,schema=columns)
df.show(truncate=False)
+-----+------------+ |Seqno|Name | +-----+------------+ |1 |john jones | |2 |tracey smith| |3 |amy sanders | +-----+------------+
In [4]:
# 첫번째 방법
import pyspark.sql.functions as F
from pyspark.sql.types import *
upperUDF = F.udf(lambda z:z.upper())
# UDF를 적용하여 "Curated Name"이라는 새로운 열 생성
# show(truncate=False): 결과 DataFrame을 출력합니다. truncate=False는
# 출력 결과의 길이를 자르지 않도록 설정합니다.
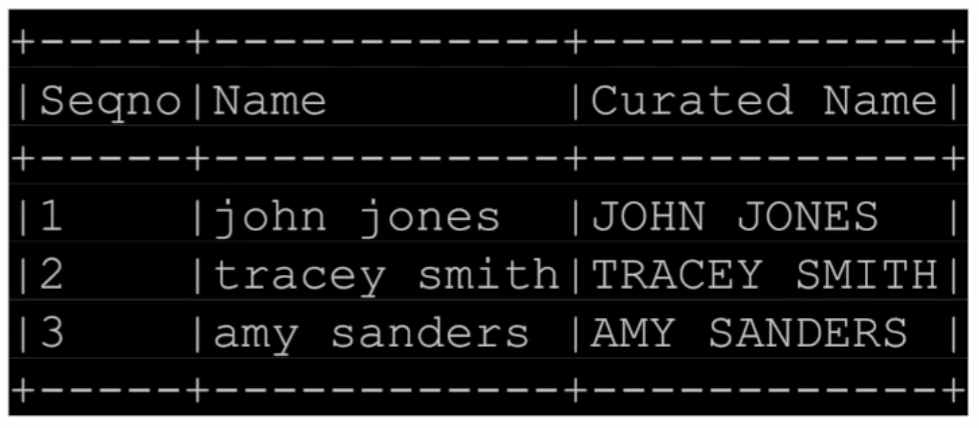
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)
+-----+------------+------------+ |Seqno|Name |Curated Name| +-----+------------+------------+ |1 |john jones |JOHN JONES | |2 |tracey smith|TRACEY SMITH| |3 |amy sanders |AMY SANDERS | +-----+------------+------------+
In [5]:
# 두번째 방법
def upper_udf(s):
return s.upper()
In [6]:
# 리턴은 String
upperUDF = F.udf(upper_udf, StringType())
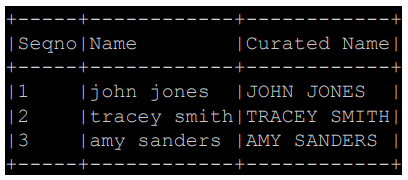
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)
+-----+------------+------------+ |Seqno|Name |Curated Name| +-----+------------+------------+ |1 |john jones |JOHN JONES | |2 |tracey smith|TRACEY SMITH| |3 |amy sanders |AMY SANDERS | +-----+------------+------------+
In [9]:
# "Name" 열에 upperUDF라는 사용자 정의 함수(UDF)를 적용
# alias 메서드는 PySpark DataFrame에서 열의 이름을 변경하는 데 사용
df.select("Name", upperUDF("Name").alias("Curated Name")).show()
+------------+------------+ | Name|Curated Name| +------------+------------+ | john jones| JOHN JONES| |tracey smith|TRACEY SMITH| | amy sanders| AMY SANDERS| +------------+------------+
In [8]:
from pyspark.sql.functions import pandas_udf
import pandas as pd
# 데코레이터는 Pandas UDF를 정의하기 위해 사용됩니다. StringType()은 UDF의 반환 유형을 지정
@pandas_udf(StringType())
# upper_udf_f라는 Pandas UDF를 정의
'''(s: pd.Series) -> pd.Series:: 함수의 매개변수와 반환 유형을 지정합니다.
이 함수는 pd.Series 타입의 매개변수 s를 받아들이고, pd.Series 타입의 값을 반환합니다.
즉, 함수는 pandas Series를 입력으로 받아들이고, pandas Series를 반환'''
def upper_udf_f(s: pd.Series) -> pd.Series:
# s.str.upper()는 pandas Series에 대해 각 문자열 요소를 대문자로 변환하는 연산
return s.str.upper()
In [10]:
# 위에서 정의한 파이썬 upper 함수를 그대로 사용
upperUDF = spark.udf.register("upper_udf", upper_udf_f)
spark.sql("SELECT upper_udf('aBcD')").show()
+---------------+ |upper_udf(aBcD)| +---------------+ | ABCD| +---------------+
In [11]:
df.select("name", upperUDF("name")).show()
+------------+-----------------+ | name|upper_udf_f(name)| +------------+-----------------+ | john jones| JOHN JONES| |tracey smith| TRACEY SMITH| | amy sanders| AMY SANDERS| +------------+-----------------+
In [12]:
df.createOrReplaceTempView("test")
spark.sql("""
SELECT name, upper_udf(name) `Curated Name` FROM test
""").show()
+------------+------------+ | name|Curated Name| +------------+------------+ | john jones| JOHN JONES| |tracey smith|TRACEY SMITH| | amy sanders| AMY SANDERS| +------------+------------+
Dataframe/SQL에 UDF 사용해보기 #2
In [13]:
data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
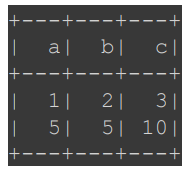
df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b")).show()
+---+---+---+ | a| b| c| +---+---+---+ | 1| 2| 3| | 5| 5| 10| +---+---+---+
In [14]:
def plus(x, y):
return x + y
# UDF 등록(register)
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2) sum").show()
+---+ |sum| +---+ | 3| +---+
In [15]:
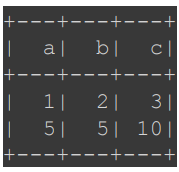
df.withColumn("p", plusUDF("a", "b")).show()
+---+---+---+ | a| b| p| +---+---+---+ | 1| 2| 3| | 5| 5| 10| +---+---+---+
In [16]:
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) p FROM test").show()
+---+---+---+ | a| b| p| +---+---+---+ | 1| 2| 3| | 5| 5| 10| +---+---+---+
Dataframe에 UDAF 사용해보기
In [17]:
from pyspark.sql.functions import pandas_udf
import pandas as pd
# Define the UDF
@pandas_udf(FloatType())
def average_udf_f(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average_udf', average_udf_f)
spark.sql('SELECT average_udf(a) FROM test').show()
+--------------+ |average_udf(a)| +--------------+ | 3.0| +--------------+
In [18]:
'''df: PySpark DataFrame입니다. agg: 집계(aggregation)를 수행하는 메서드입니다.
여기서는 averageUDF("b").alias("count")를 통해 "b" 열에 대한 평균을 계산하고,
그 결과를 "count"라는 열로 별칭 지정합니다.'''
df.agg(averageUDF("b").alias("count")).show()
+-----+ |count| +-----+ | 3.5| +-----+
DataFrame에 explode 사용해보기
In [19]:
arrayData = [
('James',['Java','Scala'],{'hair':'black','eye':'brown'}),
('Michael',['Spark','Java',None],{'hair':'brown','eye':None}),
('Robert',['CSharp',''],{'hair':'red','eye':''}),
('Washington',None,None),
('Jefferson',['1','2'],{})]
df = spark.createDataFrame(data=arrayData, schema = ['name','knownLanguages','properties'])
df.show()
+----------+-------------------+--------------------+
| name| knownLanguages| properties|
+----------+-------------------+--------------------+
| James| [Java, Scala]|{eye -> brown, ha...|
| Michael|[Spark, Java, null]|{eye -> null, hai...|
| Robert| [CSharp, ]|{eye -> , hair ->...|
|Washington| null| null|
| Jefferson| [1, 2]| {}|
+----------+-------------------+--------------------+
In [20]:
# knownLanguages 필드를 언어별로 짤라서 새로운 레코드로 생성
from pyspark.sql.functions import explode
df2 = df.select(df.name,explode(df.knownLanguages))
df2.printSchema()
df2.show()
root |-- name: string (nullable = true) |-- col: string (nullable = true) +---------+------+ | name| col| +---------+------+ | James| Java| | James| Scala| | Michael| Spark| | Michael| Java| | Michael| null| | Robert|CSharp| | Robert| | |Jefferson| 1| |Jefferson| 2| +---------+------+
하나의 레코드에서 다수의 레코드를 만들어내는 예제 (Order to 1+ Items)
In [21]:
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/orders.csv
--2024-01-27 14:44:39-- https://s3-geospatial.s3.us-west-2.amazonaws.com/orders.csv Resolving s3-geospatial.s3.us-west-2.amazonaws.com (s3-geospatial.s3.us-west-2.amazonaws.com)... 52.218.242.153, 3.5.84.22, 3.5.86.146, ... Connecting to s3-geospatial.s3.us-west-2.amazonaws.com (s3-geospatial.s3.us-west-2.amazonaws.com)|52.218.242.153|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 89951 (88K) [text/csv] Saving to: ‘orders.csv’ orders.csv 100%[===================>] 87.84K --.-KB/s in 0.08s 2024-01-27 14:44:40 (1.07 MB/s) - ‘orders.csv’ saved [89951/89951]
In [22]:
!head -5 orders.csv
order_id items
860196503764 [{"name": "DAILY SPF", "quantity": 1, "id": 1883727790094}]
860292645076 [{"name": "DAILY SPF \u2014 Bundle Set", "quantity": 1, "id": 1883875377166}]
860320956628 [{"name": "DAILY SPF", "quantity": 1, "id": 1883919974414}]
860321513684 [{"name": "DAILY SPF", "quantity": 1, "id": 1883920793614}]
Spark으로 해보기
In [23]:
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, LongType
order = spark.read.options(delimiter='\t').option("header","true").csv("orders.csv")
In [24]:
order.show()
+------------+--------------------+
| order_id| items|
+------------+--------------------+
|860196503764|[{"name": "DAILY ...|
|860292645076|[{"name": "DAILY ...|
|860320956628|[{"name": "DAILY ...|
|860321513684|[{"name": "DAILY ...|
|862930665684|[{"name": "DAILY ...|
|862975819988|[{"name": "DAILY ...|
|862985191636|[{"name": "DAILY ...|
|870939295956|[{"name": "DAILY ...|
|880188063956|[{"name": "DAILY ...|
|933014601940|[{"name": "DAILY ...|
|934065930452|[{"name": "DAILY ...|
|938210722004|[{"name": "DAILY ...|
|944748331220|[{"name": "DAILY ...|
|862843896020|[{"name": "DAILY ...|
|862959763668|[{"name": "DAILY ...|
|870966558932|[{"name": "DAILY ...|
|887936647380|[{"name": "DAILY ...|
|908426477780|[{"name": "DAILY ...|
|921300107476|[{"name": "DAILY ...|
|932229710036|[{"name": "DAILY ...|
+------------+--------------------+
only showing top 20 rows
In [25]:
order.printSchema()
root |-- order_id: string (nullable = true) |-- items: string (nullable = true)
In [26]:
# 데이터프레임을 이용해서 해보기
struct = ArrayType(
StructType([
StructField("name", StringType()),
StructField("id", StringType()),
StructField("quantity", LongType())
])
)
In [27]:
order.withColumn("item", explode(from_json("items", struct))).show(truncate=False)
+------------+-----------------------------------------------------------------------------+------------------------------------------+
|order_id |items |item |
+------------+-----------------------------------------------------------------------------+------------------------------------------+
|860196503764|[{"name": "DAILY SPF", "quantity": 1, "id": 1883727790094}] |{DAILY SPF, 1883727790094, 1} |
|860292645076|[{"name": "DAILY SPF \u2014 Bundle Set", "quantity": 1, "id": 1883875377166}]|{DAILY SPF — Bundle Set, 1883875377166, 1}|
|860320956628|[{"name": "DAILY SPF", "quantity": 1, "id": 1883919974414}] |{DAILY SPF, 1883919974414, 1} |
|860321513684|[{"name": "DAILY SPF", "quantity": 1, "id": 1883920793614}] |{DAILY SPF, 1883920793614, 1} |
|862930665684|[{"name": "DAILY SPF", "quantity": 1, "id": 1887913672718}] |{DAILY SPF, 1887913672718, 1} |
|862975819988|[{"name": "DAILY SPF", "quantity": 1, "id": 1887985827854}] |{DAILY SPF, 1887985827854, 1} |
|862985191636|[{"name": "DAILY SPF \u2014 Bundle Set", "quantity": 1, "id": 1887999164430}]|{DAILY SPF — Bundle Set, 1887999164430, 1}|
|870939295956|[{"name": "DAILY SPF", "quantity": 1, "id": 1900142264334}] |{DAILY SPF, 1900142264334, 1} |
|880188063956|[{"name": "DAILY SPF", "quantity": 1, "id": 1914170572814}] |{DAILY SPF, 1914170572814, 1} |
|933014601940|[{"name": "DAILY SPF", "quantity": 1, "id": 1995572117518}] |{DAILY SPF, 1995572117518, 1} |
|934065930452|[{"name": "DAILY SPF", "quantity": 1, "id": 1997094813710}] |{DAILY SPF, 1997094813710, 1} |
|938210722004|[{"name": "DAILY SPF", "quantity": 1, "id": 2003241992206}] |{DAILY SPF, 2003241992206, 1} |
|944748331220|[{"name": "DAILY SPF", "quantity": 1, "id": 2013027794958}] |{DAILY SPF, 2013027794958, 1} |
|862843896020|[{"name": "DAILY SPF \u2014 Bundle Set", "quantity": 1, "id": 1887779946510}]|{DAILY SPF — Bundle Set, 1887779946510, 1}|
|862959763668|[{"name": "DAILY SPF", "quantity": 1, "id": 1887960727566}] |{DAILY SPF, 1887960727566, 1} |
|870966558932|[{"name": "DAILY SPF", "quantity": 1, "id": 1900184338446}] |{DAILY SPF, 1900184338446, 1} |
|887936647380|[{"name": "DAILY SPF", "quantity": 1, "id": 1926287851534}] |{DAILY SPF, 1926287851534, 1} |
|908426477780|[{"name": "DAILY SPF", "quantity": 1, "id": 1960246870030}] |{DAILY SPF, 1960246870030, 1} |
|921300107476|[{"name": "DAILY SPF", "quantity": 1, "id": 1979032993806}] |{DAILY SPF, 1979032993806, 1} |
|932229710036|[{"name": "DAILY SPF", "quantity": 1, "id": 1994496901134}] |{DAILY SPF, 1994496901134, 1} |
+------------+-----------------------------------------------------------------------------+------------------------------------------+
only showing top 20 rows
In [28]:
order_items = order.withColumn("item", explode(from_json("items", struct))).drop("items")
In [29]:
order_items.show(5)
+------------+--------------------+
| order_id| item|
+------------+--------------------+
|860196503764|{DAILY SPF, 18837...|
|860292645076|{DAILY SPF — Bund...|
|860320956628|{DAILY SPF, 18839...|
|860321513684|{DAILY SPF, 18839...|
|862930665684|{DAILY SPF, 18879...|
+------------+--------------------+
only showing top 5 rows
In [30]:
order_items.printSchema()
root |-- order_id: string (nullable = true) |-- item: struct (nullable = true) | |-- name: string (nullable = true) | |-- id: string (nullable = true) | |-- quantity: long (nullable = true)
In [31]:
order_items.createOrReplaceTempView("order_items")
In [32]:
spark.sql("""
SELECT order_id, CAST(average_udf(item.quantity) as decimal) avg_count
FROM order_items
GROUP BY 1
ORDER BY 2 DESC""").show(5)
+-------------+---------+ | order_id|avg_count| +-------------+---------+ |1816674631892| 500| |1821860430036| 300| |2186043064532| 208| |2143034474708| 200| |2118824558804| 200| +-------------+---------+ only showing top 5 rows
In [33]:
spark.sql("""SELECT item.quantity FROM order_items WHERE order_id = '1816674631892'""").show()
+--------+ |quantity| +--------+ | 500| +--------+
In [34]:
spark.catalog.listTables()
Out[34]:
[Table(name='order_items', database=None, description=None, tableType='TEMPORARY', isTemporary=True), Table(name='test', database=None, description=None, tableType='TEMPORARY', isTemporary=True)]
In [35]:
# 많은 함수중 만든 UDF를 확인할수 있음
for f in spark.catalog.listFunctions():
print(f[0])
! % & * + - / < <= <=> = == > >= ^ abs acos acosh add_months aes_decrypt aes_encrypt aggregate and any approx_count_distinct approx_percentile array array_agg array_contains array_distinct array_except array_intersect array_join array_max array_min array_position array_remove array_repeat array_size array_sort array_union arrays_overlap arrays_zip ascii asin asinh assert_true atan atan2 atanh average_udf avg base64 bigint bin binary bit_and bit_count bit_get bit_length bit_or bit_xor bool_and bool_or boolean bround btrim cardinality cast cbrt ceil ceiling char char_length character_length chr coalesce collect_list collect_set concat concat_ws contains conv corr cos cosh cot count count_if count_min_sketch covar_pop covar_samp crc32 csc cume_dist current_catalog current_database current_date current_timestamp current_timezone current_user date date_add date_format date_from_unix_date date_part date_sub date_trunc datediff day dayofmonth dayofweek dayofyear decimal decode degrees dense_rank div double e element_at elt encode endswith every exists exp explode explode_outer expm1 extract factorial filter find_in_set first first_value flatten float floor forall format_number format_string from_csv from_json from_unixtime from_utc_timestamp get_json_object getbit greatest grouping grouping_id hash hex histogram_numeric hour hypot if ifnull ilike in initcap inline inline_outer input_file_block_length input_file_block_start input_file_name instr int isnan isnotnull isnull java_method json_array_length json_object_keys json_tuple kurtosis lag last last_day last_value lcase lead least left length levenshtein like ln locate log log10 log1p log2 lower lpad ltrim make_date make_dt_interval make_interval make_timestamp make_ym_interval map map_concat map_contains_key map_entries map_filter map_from_arrays map_from_entries map_keys map_values map_zip_with max max_by md5 mean min min_by minute mod monotonically_increasing_id month months_between named_struct nanvl negative next_day not now nth_value ntile nullif nvl nvl2 octet_length or overlay parse_url percent_rank percentile percentile_approx pi plus pmod posexplode posexplode_outer position positive pow power printf quarter radians raise_error rand randn random range rank reflect regexp regexp_extract regexp_extract_all regexp_like regexp_replace regr_avgx regr_avgy regr_count regr_r2 repeat replace reverse right rint rlike round row_number rpad rtrim schema_of_csv schema_of_json sec second sentences sequence session_window sha sha1 sha2 shiftleft shiftright shiftrightunsigned shuffle sign signum sin sinh size skewness slice smallint some sort_array soundex space spark_partition_id split split_part sqrt stack startswith std stddev stddev_pop stddev_samp str_to_map string struct substr substring substring_index sum tan tanh timestamp timestamp_micros timestamp_millis timestamp_seconds tinyint to_binary to_csv to_date to_json to_number to_timestamp to_unix_timestamp to_utc_timestamp transform transform_keys transform_values translate trim trunc try_add try_avg try_divide try_element_at try_multiply try_subtract try_sum try_to_binary try_to_number typeof ucase unbase64 unhex unix_date unix_micros unix_millis unix_seconds unix_timestamp upper upper_udf uuid var_pop var_samp variance version weekday weekofyear when width_bucket window xpath xpath_boolean xpath_double xpath_float xpath_int xpath_long xpath_number xpath_short xpath_string xxhash64 year zip_with | ~
'하둡,spark' 카테고리의 다른 글
| UDF(User Defined Function) 사용해보기. (1) | 2024.01.25 |
|---|---|
| spark sql에서 join (0) | 2024.01.25 |
| spark SQL (1) | 2024.01.25 |
| spark 데이터프레임 실습5 (0) | 2024.01.24 |
| spark 데이터프레임 실습4 (0) | 2024.01.24 |