UDF (User Defined Function):
- 개요:**
- **UDF (User Defined Function):** 사용자가 직접 정의한 함수로, Spark에서는 DataFrame이나 SQL에서 사용할 수 있는 사용자 정의 함수를 의미합니다.
- 데이터프레임의 경우 .withColumn 함수와 같이 사용하는 것이 일반적, spark SQL에서도 사용 가능함
- UDF를 사용하면 개발자는 Spark의 기본 제공 함수 외에도 자신만의 사용자 정의 함수를 생성하여 데이터 처리 작업을 수행할 수 있습니다. - 종류:**
- **Scalar 함수:**
- 개별 데이터 레코드에 적용되는 함수로, 각 레코드에 대해 개별적으로 값을 반환합니다.
- 예시: `UPPER`, `LOWER`와 같은 문자열 처리 함수 등이 Scalar 함수에 해당합니다.
- **Aggregation 함수 (UDAF - User Defined Aggregation Function):**
- 여러 레코드에 대한 집계 결과를 반환하는 함수입니다.
- 예시: `SUM`, `MIN`, `MAX`와 같은 집계 함수 등이 Aggregation 함수에 해당합니다. - 사용 방법:**
- **DataFrame API:**
- Scala, Python, Java 등의 언어를 사용하여 UDF를 정의하고, DataFrame의 `withColumn` 또는 `select` 등의 함수를 통해 적용할 수 있습니다.
- **SQL:**
- SQL에서는 `CREATE FUNCTION`을 사용하여 UDF를 정의하고, 이를 SQL 문에서 활용할 수 있습니다.
- `REGISTER FUNCTION` 등을 사용하여 Spark에서 사용자 정의 함수를 등록할 수도 있습니다. - 예시:**
- **Scala에서의 DataFrame UDF:**
import org.apache.spark.sql.functions.udf
val myUDF = udf((value: String) => {
// 사용자 정의 로직 적용
// ...
// 결과 반환
})
val resultDF = inputDF.withColumn("newColumn", myUDF(col("columnName")))
- **SQL에서의 UDF 등록 및 사용:**
-- UDF 등록
CREATE OR REPLACE FUNCTION my_udf AS
'com.example.MyUDF' USING JAR 'path/to/jar/file';
-- SQL에서 UDF 사용
SELECT my_udf(columnName) AS newColumn FROM tableName; - 그외 간단한 경우 함수 구현 방법
1) 파이썬 람다 함수:
- 간단한 함수를 한 줄로 작성할 때 주로 사용됩니다.
- 예시:
add = lambda x, y: x + y
result = add(3, 5)
print(result) # 출력: 8
2) 파이썬 일반 함수:**
- 더 복잡한 로직이 필요할 때 사용됩니다.
- 예시:
def add(x, y):
return x + y
result = add(3, 5)
print(result) # 출력: 8
UDF - DataFrame에 사용1
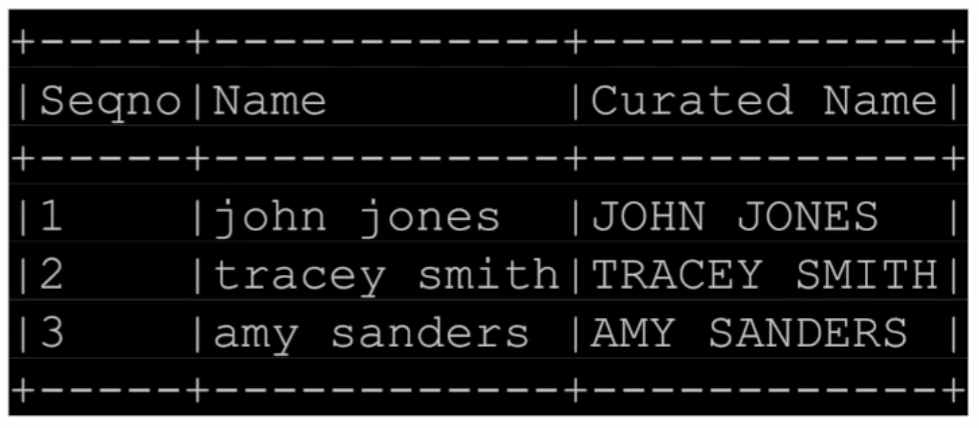
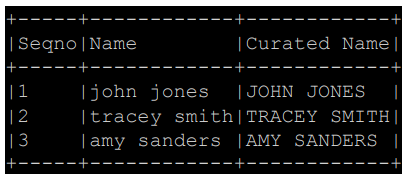
| import pyspark.sql.functions as F from pyspark.sql.types import * # 사용자 정의 함수(Upper UDF) 정의 upperUDF = F.udf(lambda z: z.upper()) # DataFrame에 새로운 컬럼 추가 및 UDF 적용 df.withColumn("Curated Name", upperUDF("Name")) 세부 설명: 1. `import pyspark.sql.functions as F`: PySpark의 함수들을 사용하기 위해 필요한 모듈을 임포트합니다. `F`는 편의상 별칭(alias)으로 사용되었습니다. 2. `from pyspark.sql.types import *`: PySpark의 데이터 타입들을 사용하기 위해 모듈을 임포트합니다. 여기서는 모든 데이터 타입을 가져옵니다. 3. `upperUDF = F.udf(lambda z: z.upper())`: PySpark의 `udf` 함수를 사용하여 사용자 정의 함수(Upper UDF)를 정의합니다. 이 UDF는 주어진 문자열을 대문자로 변환합니다. 4. `df.withColumn("Curated Name", upperUDF("Name"))`: DataFrame에 새로운 컬럼("Curated Name")을 추가하고, 이 컬럼에 `upperUDF`를 적용하여 "Name" 컬럼의 값들을 대문자로 변환합니다. |
UDF - SQL에 사용1
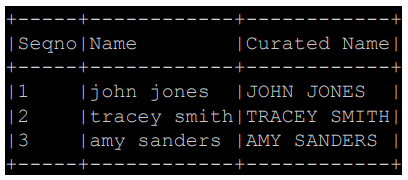
| def upper(s): return s.upper() # 사용자 정의 함수(Upper UDF) 등록 upperUDF = spark.udf.register("upper", upper) # Spark SQL을 사용하여 UDF 테스트 spark.sql("SELECT upper('aBcD')").show() # DataFrame을 테이블로 등록 df.createOrReplaceTempView("test") # DataFrame 기반 SQL에서 UDF 적용 result_df = spark.sql("""SELECT name, upper(name) AS "Curated Name" FROM test""") result_df.show() |
 |
|
UDF - DataFram에 사용2
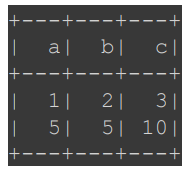
| from pyspark.sql import SparkSession from pyspark.sql import functions as F # SparkSession 생성 spark = SparkSession.builder.appName("example").getOrCreate() # 데이터 생성 data = [ {"a": 1, "b": 2}, {"a": 5, "b": 5} ] # DataFrame 생성 df = spark.createDataFrame(data) # 사용자 정의 함수(Upper UDF) 정의 sumUDF = F.udf(lambda x, y: x + y, IntegerType()) # DataFrame에 새로운 컬럼("c") 추가 및 UDF 적용 result_df = df.withColumn("c", sumUDF("a", "b")) # 결과 출력 result_df.show() |
 |
UDF - SQL에 사용 2
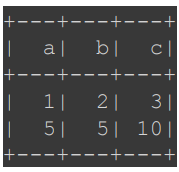
| def plus(x, y): return x + y # 사용자 정의 함수(Plus UDF) 등록(register) plusUDF = spark.udf.register("plus", plus) # Spark SQL을 사용하여 UDF 테스트 spark.sql("SELECT plus(1, 2)").show() # DataFrame을 테이블로 등록 df.createOrReplaceTempView("test") # DataFrame 기반 SQL에서 UDF 적용 result_df = spark.sql("SELECT a, b, plus(a, b) AS c FROM test") result_df.show() |
 |
|
UDF - Pandas UDF Scalar 함수 사용
| from pyspark.sql.functions import pandas_udf import pandas as pd # Pandas UDF 정의 @pandas_udf(StringType()) def upper_udf2(s: pd.Series) -> pd.Series: return s.str.upper() # Pandas UDF를 Spark SQL UDF로 등록 upperUDF = spark.udf.register("upper_udf", upper_udf2) # DataFrame에서 Pandas UDF 적용하여 결과 출력 df.select("Name", upperUDF("Name")).show() # Spark SQL에서 Pandas UDF 적용하여 결과 출력 spark.sql("""SELECT Name, upper_udf(Name) AS `Curated Name` FROM test""").show() |
 |
|
UDF - DataFrame/SQL에 Aggregation 사용
| from pyspark.sql.functions import pandas_udf import pandas as pd # Pandas UDF 정의 @pandas_udf(FloatType()) def average(v: pd.Series) -> float: return v.mean() # Pandas UDF를 Spark SQL UDF로 등록 averageUDF = spark.udf.register('average', average) # Spark SQL에서 Pandas UDF 적용하여 결과 출력 spark.sql('SELECT average(b) FROM test').show() # DataFrame에서 Pandas UDF 적용하여 결과 출력 df.agg(averageUDF("b").alias("average")).show() |
 |
|
'하둡,spark' 카테고리의 다른 글
| UDF 실습 (0) | 2024.01.28 |
|---|---|
| spark sql에서 join (0) | 2024.01.25 |
| spark SQL (1) | 2024.01.25 |
| spark 데이터프레임 실습5 (0) | 2024.01.24 |
| spark 데이터프레임 실습4 (0) | 2024.01.24 |